
基于Only Decoder Transformer手搓LLM
概述
本项目实现了手搓一个简单的续写GPT
具体实现:从 基础二元语言模型 到 基于Transform架构(Only Decoder)的GPT模型
- BigramLanguageModel 数据集:绿野仙踪
- GPT 数据集:Openwebtext
Prepare
jupyter: 1.biagram.ipynb
Dependences
- python=3.10
1 | pip install matplotlib numpy pylzma ipykernel |
1 | # torch 安装适合cuda的版本 |
torch pip下载慢可以用conda下载,换清华源
1 | # 换源 |
训练文本准备
基础二元语言模型的数据集
下载绿野仙踪
https://www.gutenberg.org/ebooks/22566
点击Plain Text下载
做一些处理,删除一些不需要的文本,以防干扰训练
- 保留的文本从这一段开始,前面的都删掉
1 | DOROTHY AND THE WIZARD IN OZ |
- 把从这里开始到最后的部分都删掉
1 | End of Project Gutenberg's Dorothy and the Wizard in Oz, by L. Frank Baum |
然后我们得到了一个用于训练的文本,之后会在这个文本上训练一个transformer,或者至少一个后台语言模型。
如何操作文本
在进行其他工作之前,要知道如何操作文本
1 | with open('./wizard_of_oz.txt', 'rw', encoding='utf-8') as f: |
把它们放入一个我们可以使用的小词汇表中
1 | with open('./wizard_of_oz.txt', 'r', encoding='utf-8') as f: |
使用分词器
分词器(tokenizer)由encoder和decoder组成
- encoder:将这个数组的每一个元素转化为整数(比如有十个字符,那么可以编码为0-9)
1 | # 字符到索引的映射 |
现在有了一个字符级tokenizer,能够将每一个字符转化为一个整数
一些补充:
字符级tokenizer,将每一个字符转化为一个整数
- 有一个非常小的词汇表(vocabulary)和大量的词元(tokens)需要转换
- 比如说现在的文本有40000个字符,虽然词汇表(可能几十个)很小,但是有许多字符需要编码和解码
单词级tokenizer,将每一个单词转化为一个整数
- 会有非常非常多的词汇,vocab会很大
- 处理的数据集会更小,因为一个文本中需要编码解码的tokens更少
子词(subword)tokenizer:介于字符级和单词级之间
高效处理数据
在语言模型背景下,高效处理数据非常重要,拥有一个巨大的字符串可能最好的选择。
我们将使用Pytorch框架进行高效处理
1 | import torch |
将所有内容放入一个张量中,这样torch可以更高效的处理
1 | # 字符到索引的映射 |
Validation and Training Splits
将数据分为训练集和验证集。
1 | n = int(0.8*len(data)) |
二元语言模型
补充:什么叫做 bigram language model
hello 每一次预测是一个二元组(通过前一个seq预测后一个字符seq)
start of content -> h
h -> e
e -> l
l -> l
l -> 0
如何训练一个二元模型以达到我们的目标?
- 块的概念
- 从整个语料库中随机取出一小部分
- 举例:
- _ _ [ 5, 67, 21, 58, 40 ], 35 _ _ _ input
- _ _ 5, [ 67, 21, 58, 40, 35 ] _ _ _ target
用代码展示具体例子,假设block_size = 8
1 | block_size = 8 |
如果仅此,用一段序列窗口预测下一段窗口,顺序执行,这可以预测,但是不可扩展(并行)
这个过程是顺序(Sequential)的,在CPU的执行过程就是顺序的(CPU可以执行许多复杂操作,但是只能顺序执行)
而GPU可以将很多更简单的任务并行执行
所以我们可以进行大量的非常小或者计算不复杂的计算,在许多不太好但是数量大的小处理器上进行
做法:取这些小块的每一个,堆叠它们(batch)并将它们推送到GPU以大幅扩展我们的训练
1 | device = 'cuda' if torch.cuda.is_available() else 'cpu' |
(扩充)PyTorch 中的 CPU 与 GPU 性能比较
jupyter:2.torch_example.ipynb
1 | import torch |
1 | torch_rand1 = torch.rand(10000, 10000).to(device) |
结果:
- GPU:0.00801826
- CPU:0.00000000
- 从这个结果来看CPU还要快,因为矩阵的形状并不是很大,它 们只是二维的
如果把维度加大
1 | torch_rand1 = torch.rand(100, 100, 100, 100).to(device) |
- GPU:0.01275229
- CPU:0.09202719
Bigram Language Model
jupyter: 1.diagram2.ipynb
Device2GPU
跟之前一样,不过换到了GPU
1 | import torch |
1 | with open('./wizard_of_oz.txt', 'r', encoding='utf-8') as f: |
1 | # 字符到索引的映射 |
- 分割数据集, 放入GPU
1 | n = int(0.8*len(data)) |
Model
对于logits的解释,参考博客:深度学习中的 logits 、softmax,TensorFlow中的 tf.nn.softmax_cross_entropy_with_logits 、tf.nn.sparse_soft…对比_tf.logit-CSDN博客
1 | class BigramLanguageModel(nn.Module): |
- 计算损失的函数
1 |
|
- 优化器及训练
1 | optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate) |
- 测试
1 | context = torch.zeros((1,1), dtype=torch.long, device=device) |
1 |
|
这样的二元模型可能仍然效果不是那么好,接下来用更强大的语言模型训练
Transformer
GPT
3.gpt-v1-openwebtext.ipynb
数据集OpenWebText
下载:https://www.kaggle.com/datasets/seanandjoanna/openwebtext
训练集,验证机数据处理见 data-extract-v2.py
与Transformer架构非常接近,但是Only Decoder![]()
Model
Embedding
我们这里新增加了一个位置编码,以及改变了一个更大的词向量维度
1 | # 嵌入表 vocab_size * n_embd |
Decoder layers
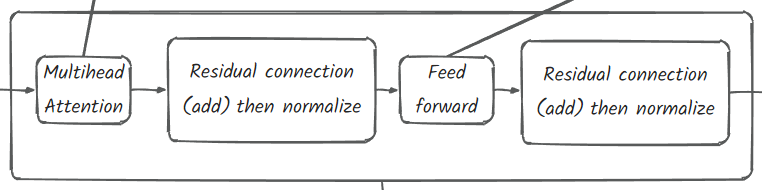
这里使用8个decoder(n_layers = 8)
1 | # 添加decoder blocks |
1 | class Block(nn.Module): |
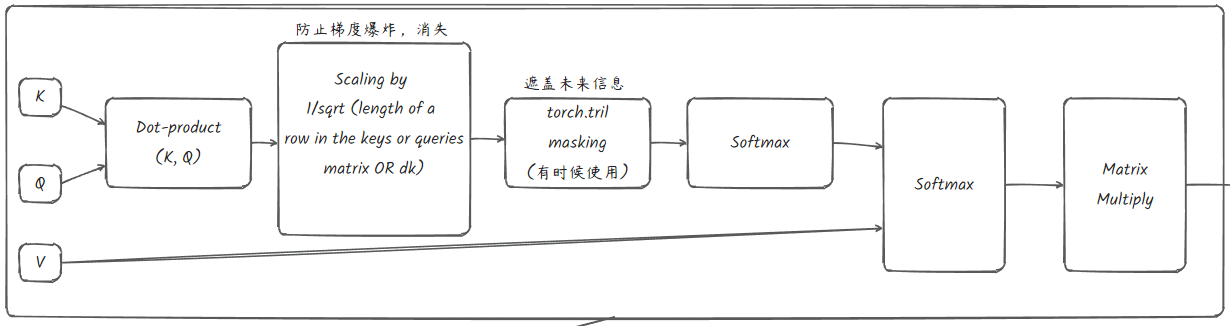
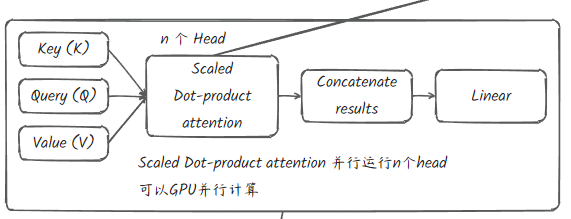
1 | class MultiHeadAttention(nn.Module): |
1 | class Head(nn.Module): |
Layer norm
在层最后正则化能够帮助收敛
1 | # layer norm final 帮助模型更好的收敛(层规范化) |
最终线性变换
最终输出的词向量线性变换为词表的维度,以方便输入softmax求得概率分布
1 | # language model head 最终投影(变换) |
Forward

1 | # index 和 targets 都是 (B, T)形状的整形张量 B:batch_size T:seqLen |
初始化参数
初始化的时候最好用标准差,实践中常用,古圣先贤的经验
1 | def _init_weights(self, module): |
Final Model
1 | class Head(nn.Module): |
训练
优化器选择Adam
1 |
|
1 | optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate) |
使用500次epoch的模型的效果: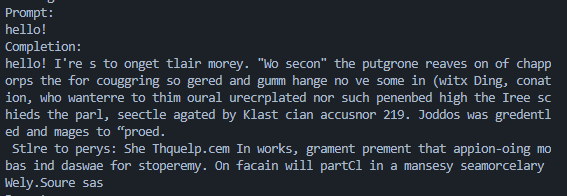
回顾历史
- RNNs
- Transformer 2017
- BERT 2018
- GPT 2018
- GPT-v2 2019
- GPT-v3 2020
