
Transformer笔记
写在前面
参考
- B站:水论文的程序猿
- datacamp: how- transformer work
- Jalammar: The Illustrated Transformer 强推 (大部分图片来源)
- DaNing的博客
什么是注意力
什么是注意力
用一张图片举例,看到下面一张图片,可能每个人有不同的关注点,但是带有一个问题:婴儿在干嘛,带着这个问题再去看,就会去思考图中哪些东西与这句话相关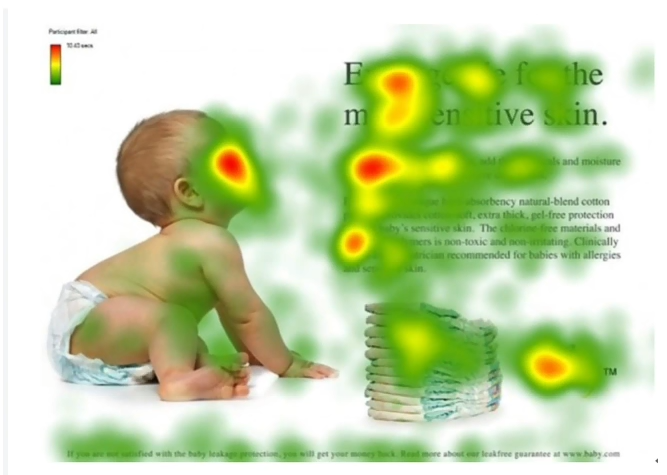
人看脸
文章看标题
段落看开头…
对于这张图而言,红色部分可能是比较重要的信息
所以注意力机制:将焦点聚焦于重要的信息上
这里先简单介绍以下论文中对注意力机制的描述(翻译了一下)
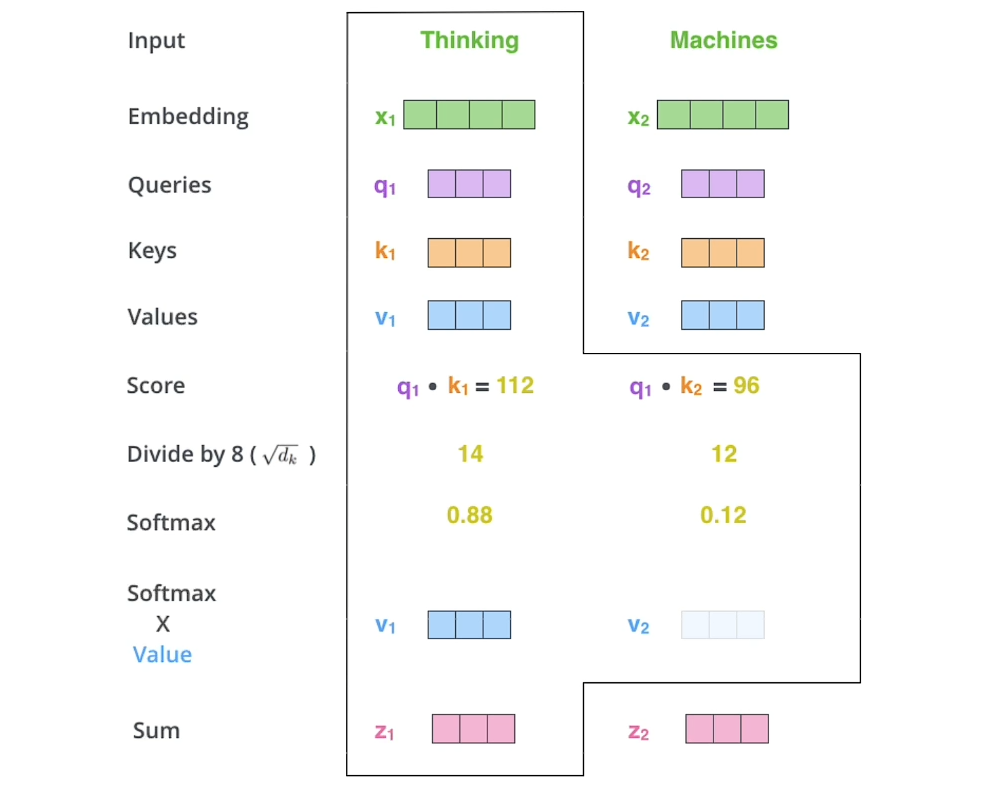
Attention Is All You Need中对注意力机制的描述:注意力函数可以描述为 由一个query和一个键值对(k-v)映射到输出的一个函数,输出是value的一个加权和
所以输出维度和value维度一样
如何做注意力
Attention score
我们假设所要判断是否要重视的对象也就是待查询对象(还没有观察这个数据前)为Q
那么数据中的所有被查询对象为 ()
如何根据 待查询对象 判断 被查询对象 的重要程度?
:::info
相似度
:::
内积:余弦相似度
内积之后可以得到每一个k对象的重要性(相似度) ()
然后对其做Softmax归一化
就得到了每一个k的重要性(相似性)权重
最后再与k对应的值v做内积,得到输出
这个output就是一个新的Value,包含了对信息的筛选(哪些重要,哪些不重要)
一般情况下k=v,也可以不等于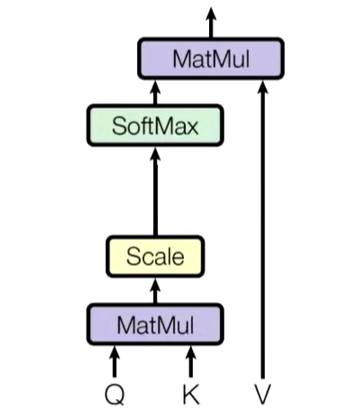
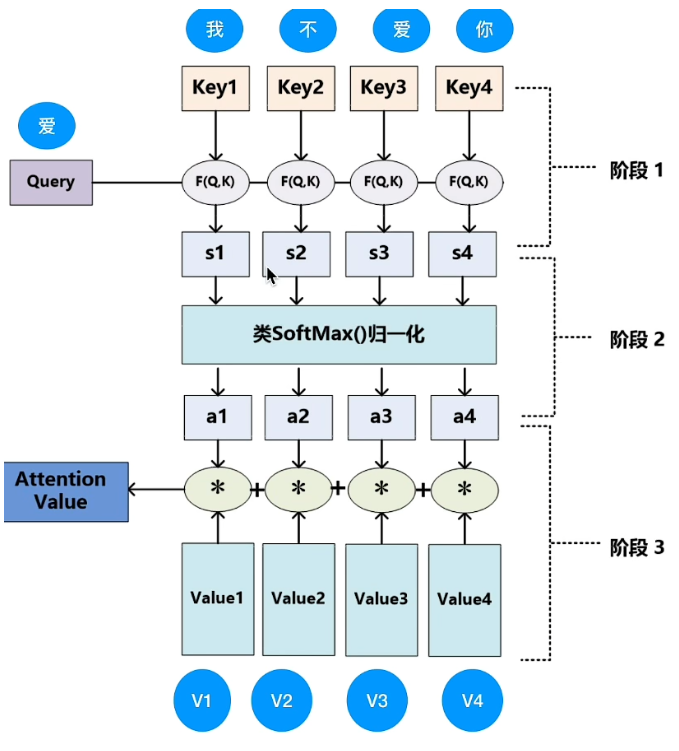
scaled
除以根号防止梯度太小
回到论文原公式,这里有一个除以根号
因为Softmax有个问题
当softmax函数中的值相差较大时,做指数化后会更加拉大两者距离
比如80,20会被压缩到接近1和接近0
so ftmax梯度消失
Attention中softmax的梯度消失及scaled原因_softmax 为什么会梯度消失-CSDN博客
Self-attention
Q,K,V是个什么鬼
关键在于QKV,来源于同一个X(同源)
都是通过三个参数矩阵得到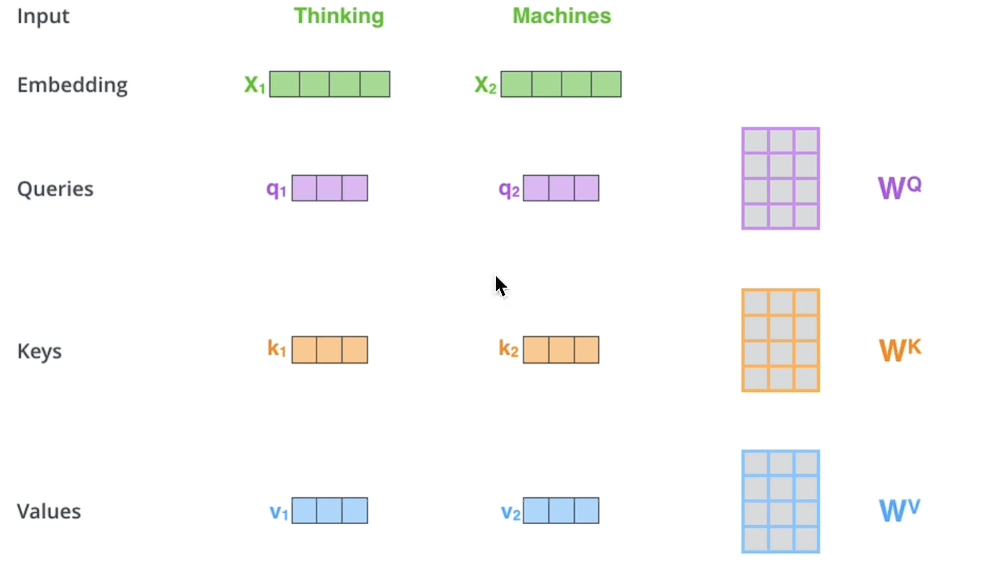
注意力计算
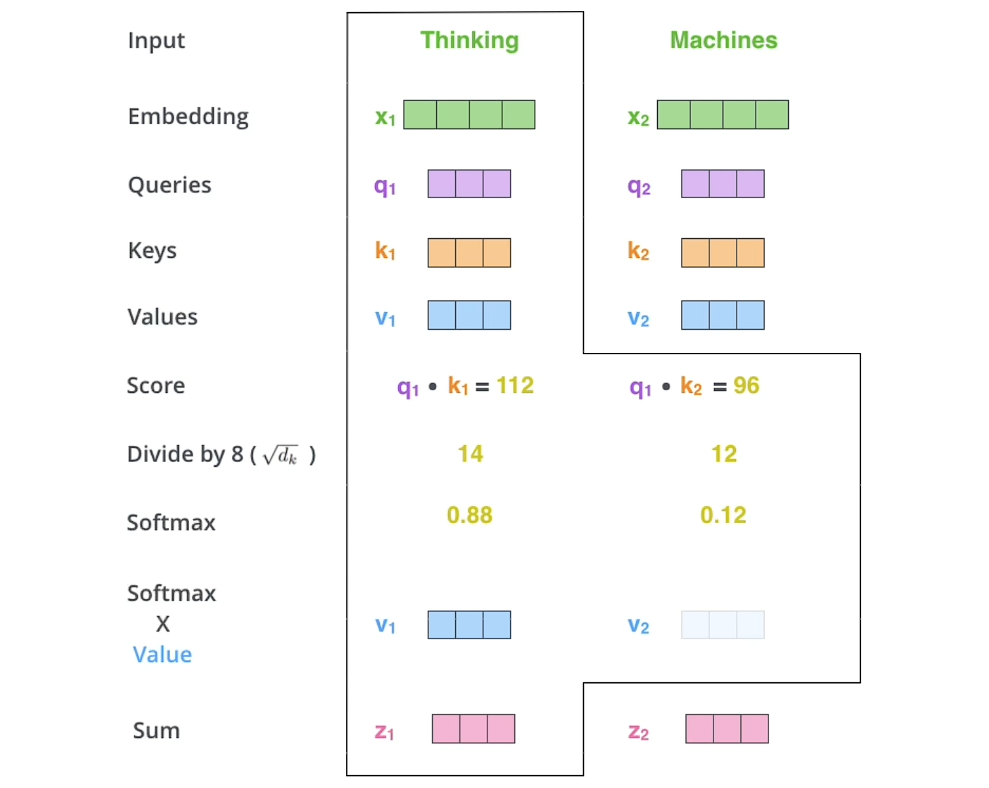
理解,给一句话,我需要知道这句话里面的每一个单词与当前单词的相关程度(重要性程度),得到一个新的向量表示
这个表示就包含了对于当前单词而言,这句话中哪些信息更加重要,削弱了不重要信息的权重
依次把这个单词的q与其他单词的k做点积,然后scale之后通过softmax,再与v做点积,得到新的向量表示
矩阵表示
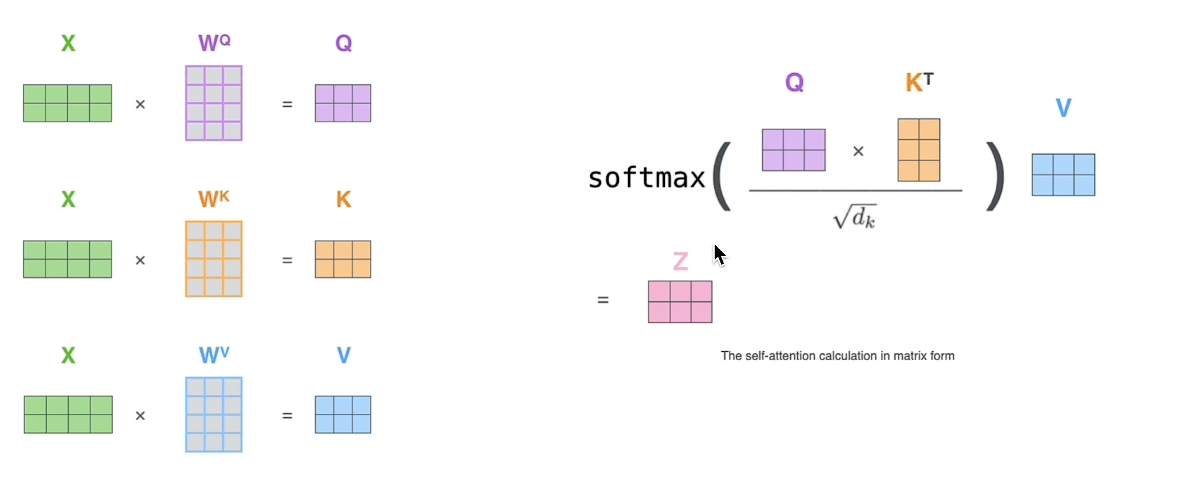
Attention和Self-Attention的区别
注意力机制是一个很宽泛的概念,没有人规定QKV是怎么来的
注意力:通过查询变量Q,去找到K里面比较重要的东西,并与老V相乘生成一个新的值V(Attention Score)
Q可以是任何东西,K,V也可以是任何东西,K往往时等同于V的(同源),K,V不同源不相等也可以
自注意机制,比较具体,属于注意力机制的一种:Q,K,V同源
虽然是用不同的参数矩阵得来的,但是Q,K,V本质上是相等的
都是输入词向量X在不同空间上的对应(X通过线性变换来的),仍然是X
好比方说:我的输入X这个词向量所表达的意思不一定准确,那我用参数矩阵使它线性变化为更准确的QKV
交叉注意力机制
如果Q与KV不相同,称为**交叉注意力机制:**Q与(K-V)不同源,但是KV同源
也可以随便自己定义注意力机制
比如Q与V同源,Q与K不同源 blabla
对比RNN,LSTM优缺点
RNN
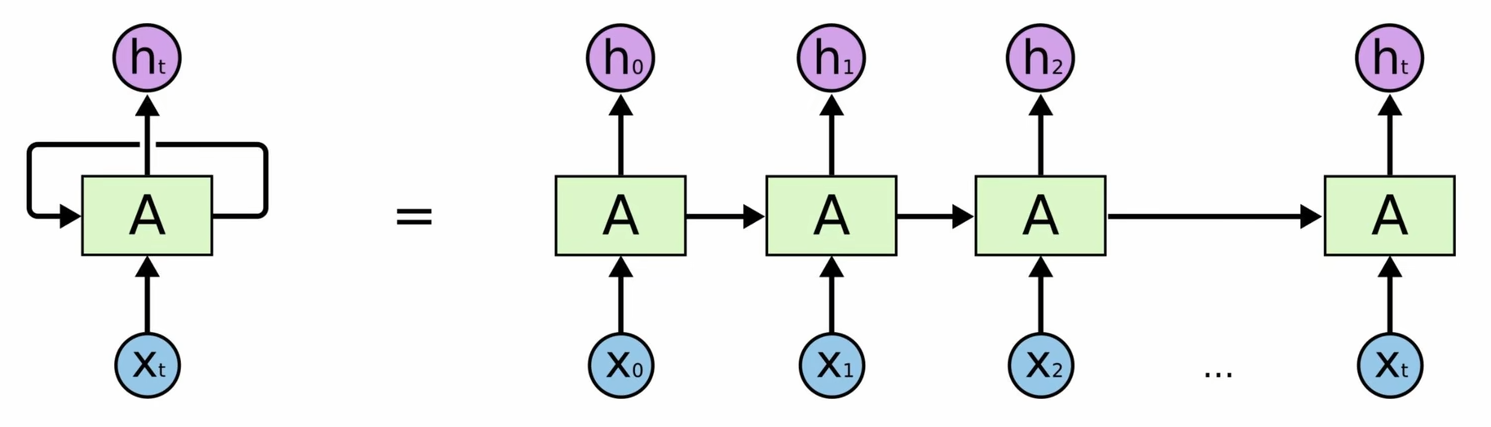
缺点:无法做长序列,梯度消失,当一句话达到50个字,效果就比较差了
LSTM
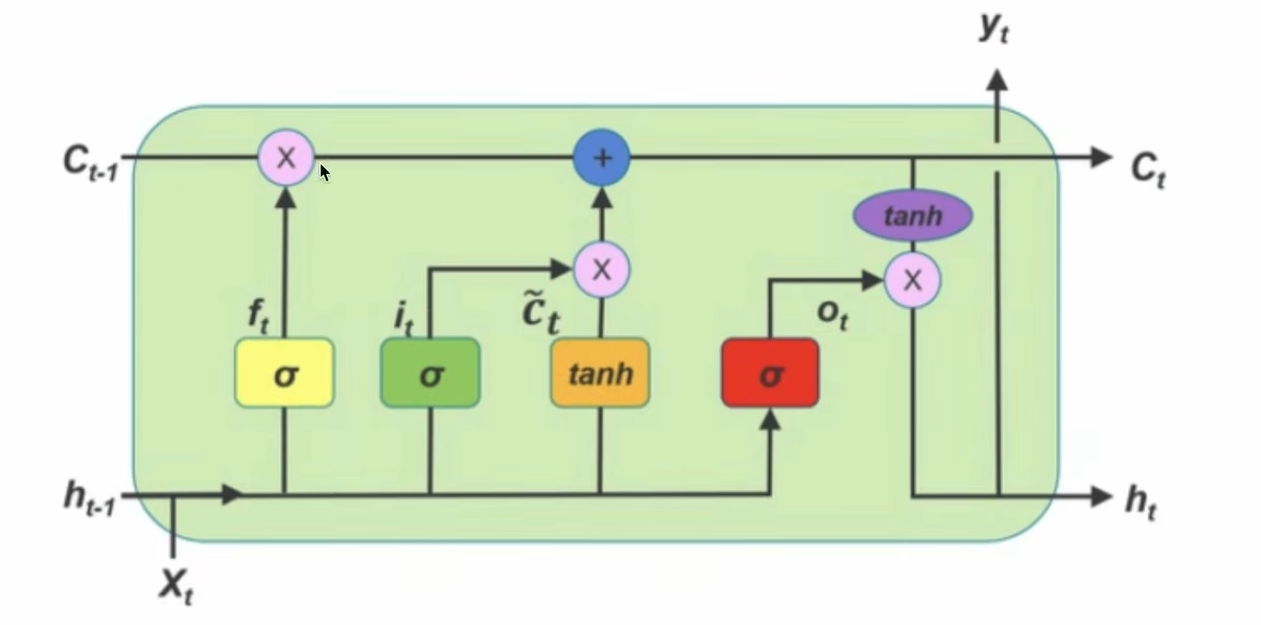
通过各种门去更新记忆,200词
Attention
RNN无法做太长序列的问题,且无法并行
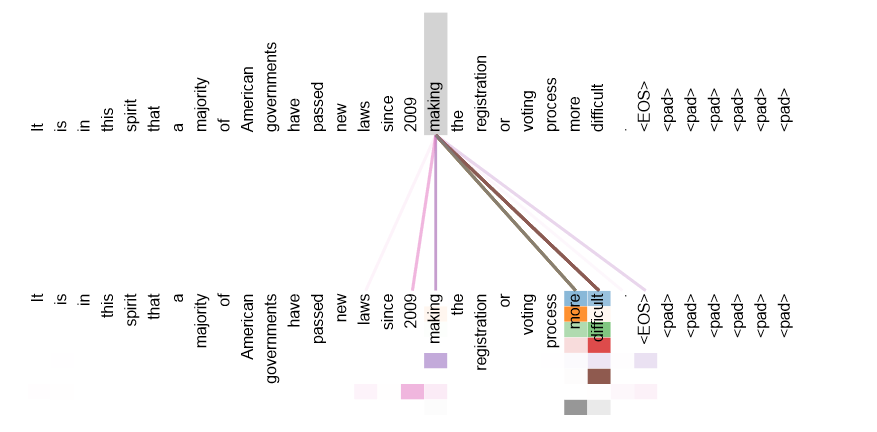
长序列:对当前单词,会计算与这段话中每一个单词的相关性(这就导致计算量更大,比如同样十个词,RNN计算十次,而tf计算10*10次)
句法特征/语义特征:Self-Attention得到的新的词向量具有语句特征和语义特征(表征更完善)
句法特征
语义特征
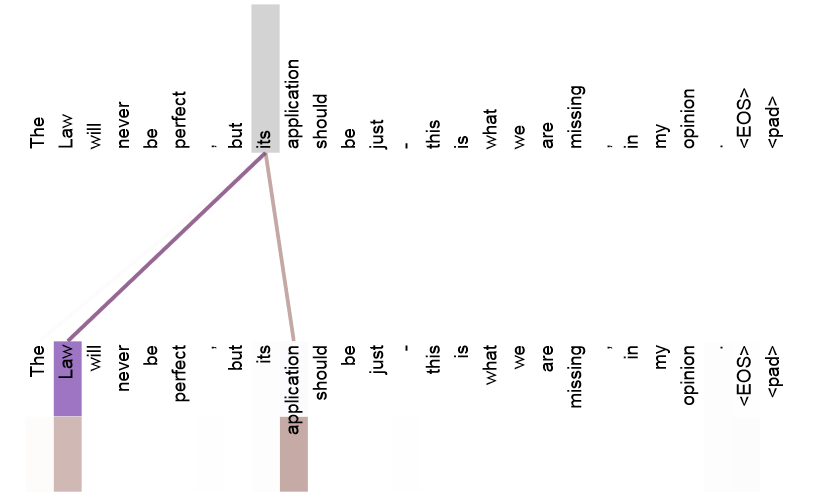
并行
知道了所有Input的Q,K,V之后,对每一个output:值,都是独立的,也就是说不会相互影响,可以并行计算
Masked Self-Attention
为什么要做这个改进:举个例子,在做文本生成任务的时候,单词是一个一个生成的,生成当前时刻的单词的时候,并不知道当前以及未来的单词的
I have a dream
>I
>I have
>I have a
>I have a dream
所以在训练时(计算Attention Core时),要模拟真实状况,要把当前时刻以后的单词给屏蔽掉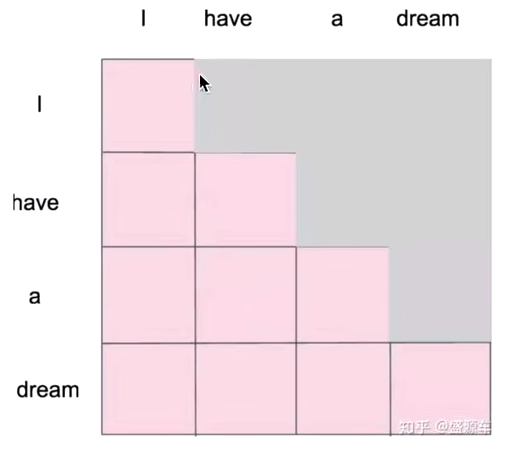
Multi-Head Self-Attention
前面讲述的Selft-Attention,将输入的词向量X转化为了新的向量表征Z
Z,相当于X有了提升,通过Multi-Head Self-Attention之后,得到的又相较于Z有了进一步的提升
多头是什么?
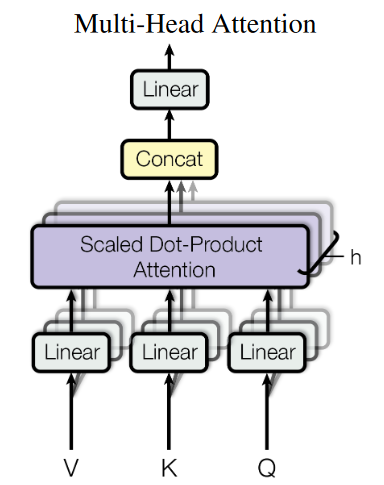
多头就是很多层Self-Attention的组合。多头的个数一般用h表示,一般h=8(8头)
对于X,并不是直接得到Z,我们把它分成了8块(Z0-Z7)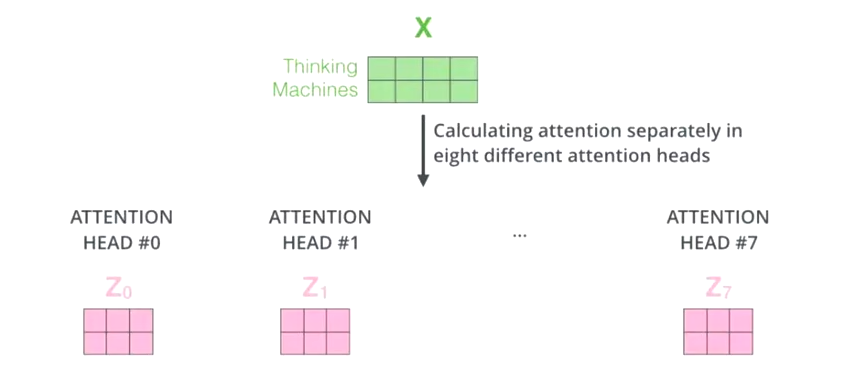
然后把Z0-Z7拼接起来,再做一次线性变换(保持和词向量一样的维度)得到Z
Position Embedding
为什么要位置编码
- Self-attention 的优点:
- 解决了长序列依赖问题
- 可以并行
- 缺点:
- 开销变大了
- 可并行导致舍弃了位置关系
解决办法
在对输入embedding后再加上position embedding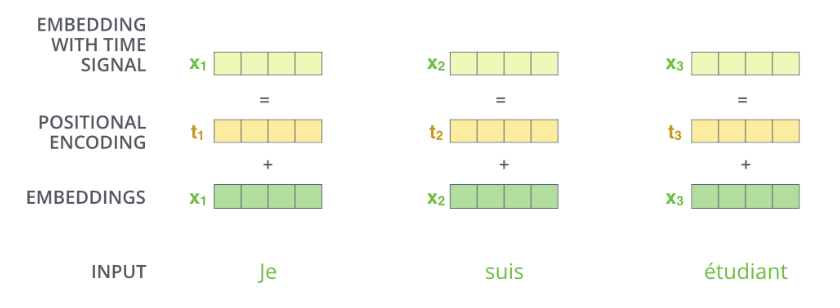
pos代表位置,i代表词向量的第i个维度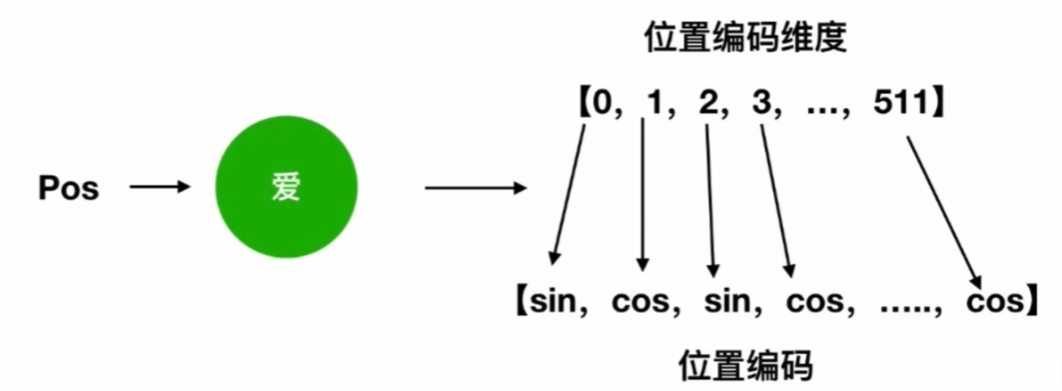
但是这样子效果不是很好
解决:可以把位置编码设置为可学习的embedding,直接训练也行!!! (BERT)
为什么有用
上述公式得到了一个特定pos位置的d维的位置向量,借助三角函数的性质:
可以得到:
一个位置的位置编码就蕴含了所有位置的信息,举例: 位置5
5 = 0+5 = 1+4 = 2+3
可以看出,对于pos+k位置的位置向量某一维21或2i十1而言,可以表示为,pos位置与k位置的位置向量的2i与21+1维的线性组合,这样的线性组合意味着位置向量中蕴含了相对位置信息。
Transformer 整体框架
流程图总结
- 流程图
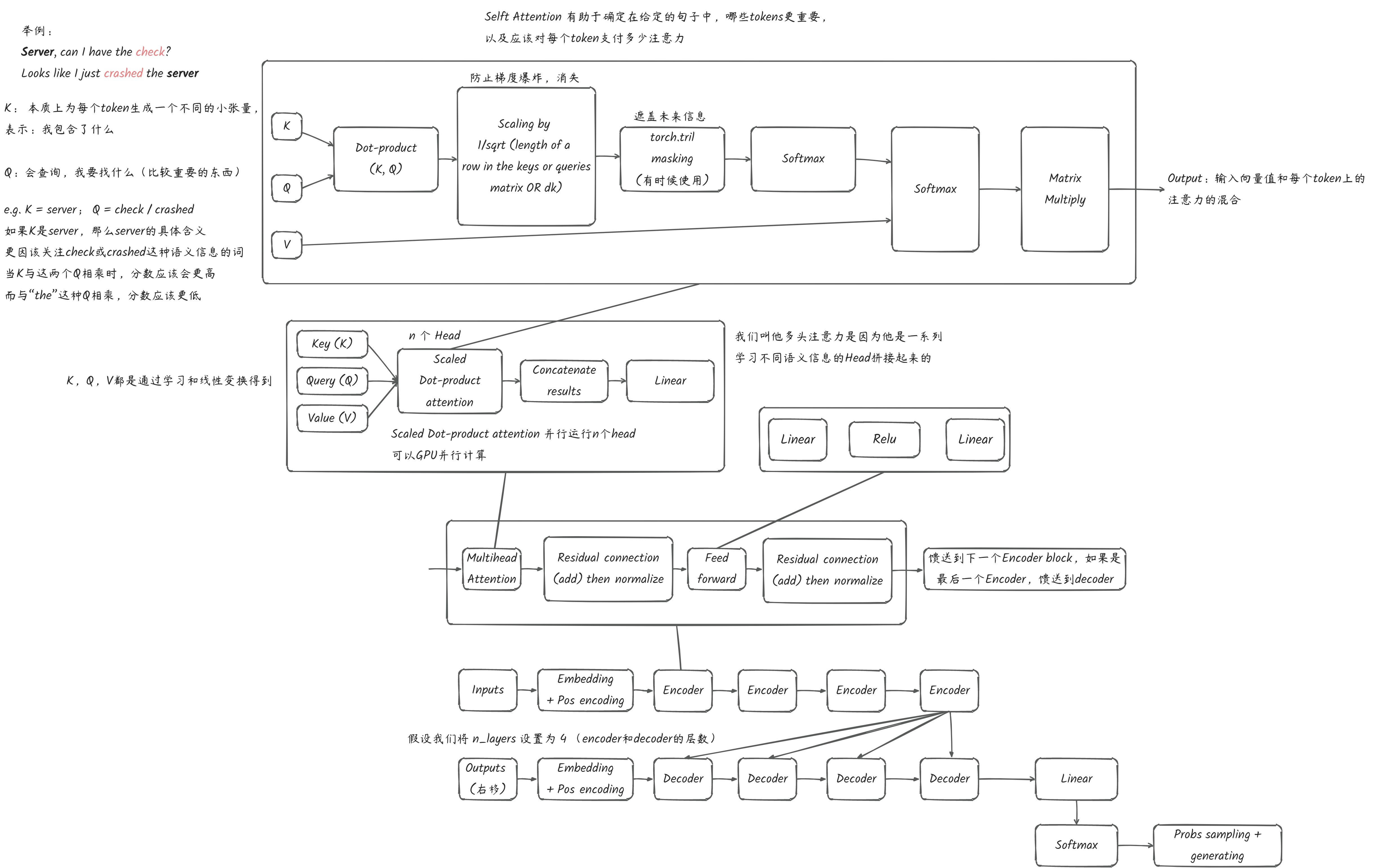
- 架构图
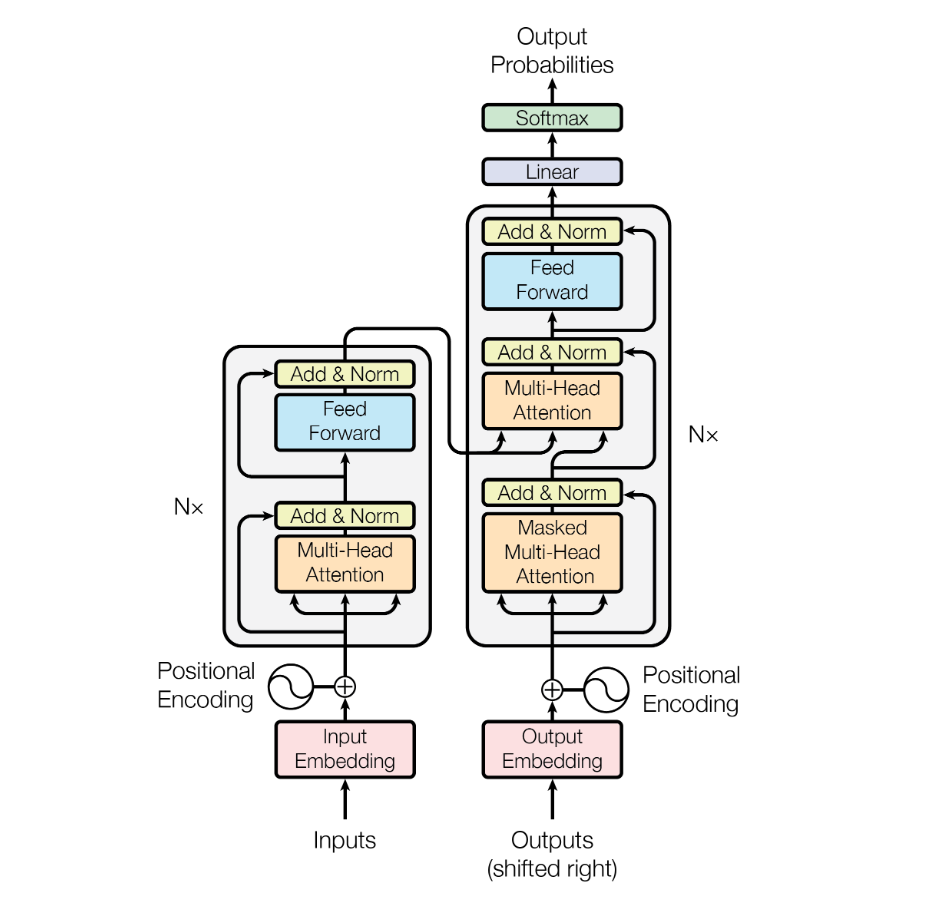
Transformer其实就是Attention的堆叠
本质是一个seq2seq模型:序列(encoder)到序列(decoder)
宏观视角
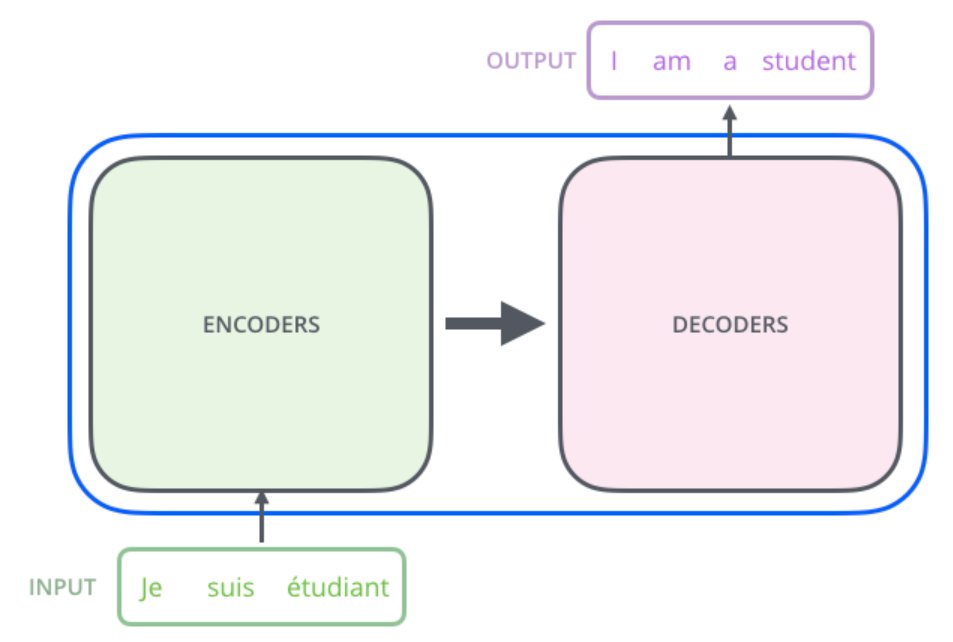
Transformer 其实就是一个黑盒,输入一个序列,输出一个序列:(以翻译举例 )
黑盒内部:编码器与解码器的连接
- 编码器:接收我们的输入并输出该输入的矩阵表示(词向量)。
- 解码器:接收编码表示并迭代生成输出
继续细化:编码组件是一堆编码器(论文中将六个编码器堆叠在一起——六这个数字并没有什么神奇之处,当然可以尝试其他排列方式)。解码组件是一堆相同数量的解码器。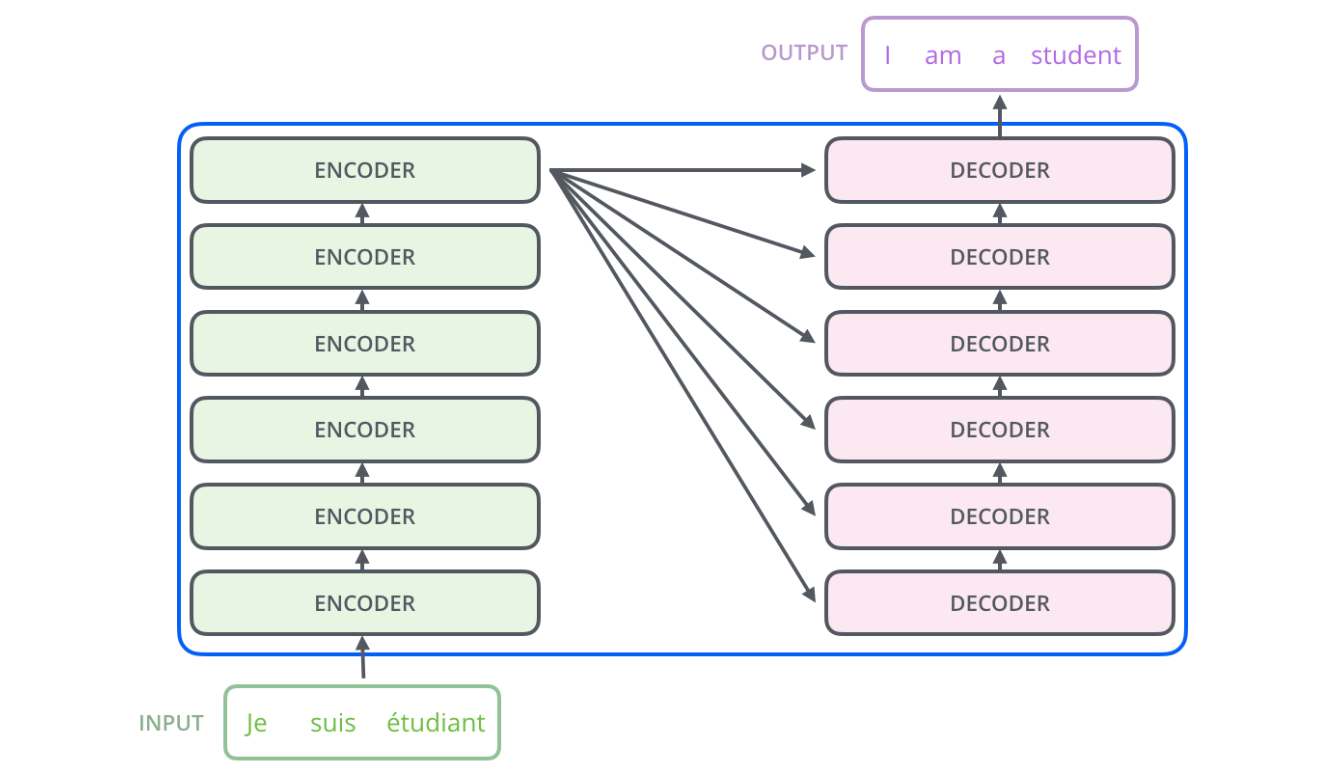
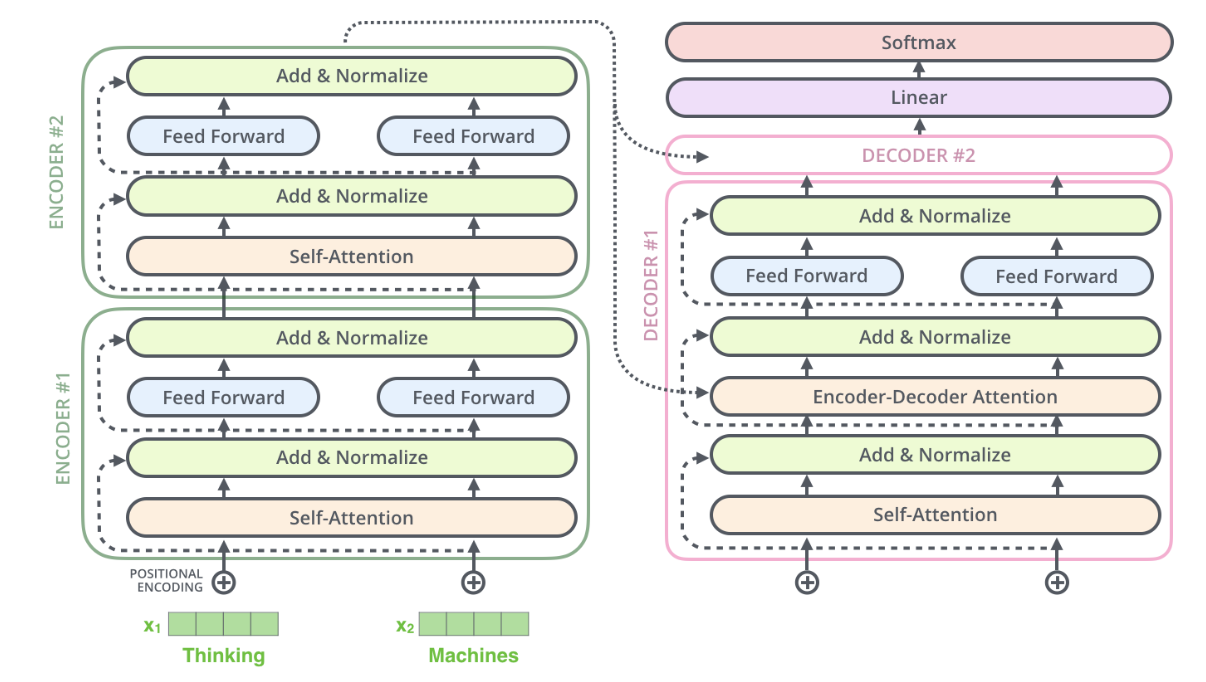
Encoder
一个编码器包括两个子层(只有最后一层编码其会有右箭头与Decoder连接!!)
- Self-Attention
- Feed Forward
每一个子层的传输过程会有一个残差网络+归一化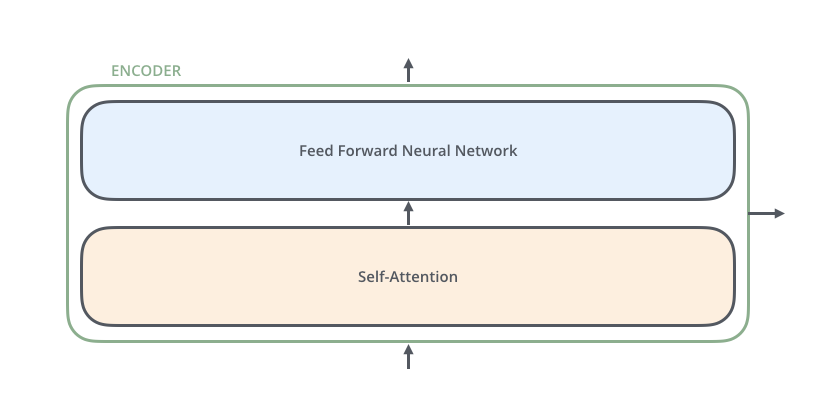
详细过程: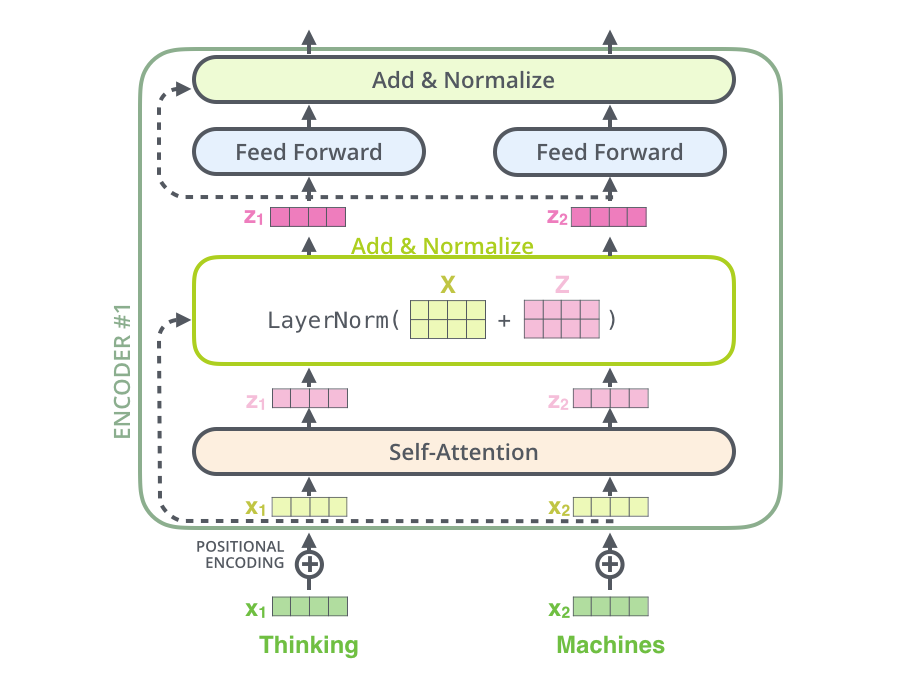
Thinking
–》得到 x1(绿色词向量)(可以通过一些简单的方法:one-hot、word2vec、embedding等得到) + 叠加位置编码得到x1(黄色词向量),
–》输入到Self-Attention中做注意力,得到z1(x1与x1,x2…拼接起来的句子做了自注意力后的词向量表征),表征仍然是thinking(拥有了位置属性,句法、语义属性)
–》残差网络(避免梯度消失),标准化(LayerNorm),也能够限制区间,避免梯度爆炸
残差:比如有
w3(w2(w1x+b1)+b2)+b3 ,如果w_i都特别小,那x就相当于没了
解决:w3(w2(w1x+b1)+b2)+b3+x (不太严谨的理解)
–》前馈神经网络,得到r1新的thinking表征(提升了表征的能力)
前馈:
前面每一步都在做线性变换 wx+b,叠加永远都是线性变换,所以需要非线性变换
核心:让词向量表征更精准
Decoder
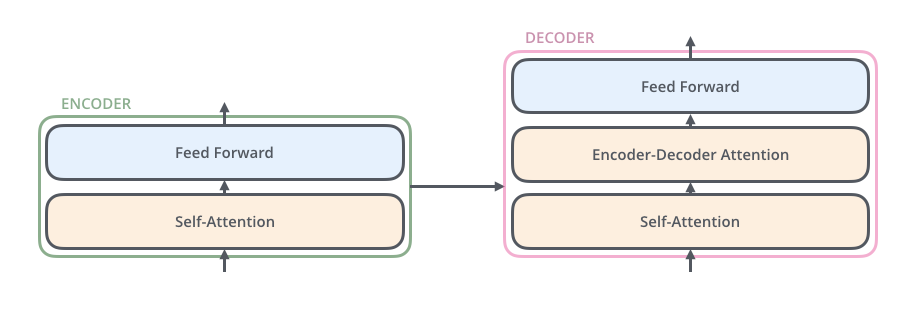
接受编码器生成的词向量,去生成翻译的结果(以翻译举例)
解码器的Self-Attention再编码已经生成的单词,举例:
目标词:我是一个学生
编码器输出:“我”的词向量,解码器对“我”进行编码
编码器输出:“是”的词向量,解码器对“我是”进行编码
有一种mask-self-atten的味道
- 训练阶段:目标词 我是一个学生 是已知的,self-atten对“我是一个学生”做计算
- 测试阶段:
- 第一次 对 “我” 计算
- 第二次 对 “我是”计算
Encoder-Decoder Attention
解码器提供Q,编码器提供K,V
流程图: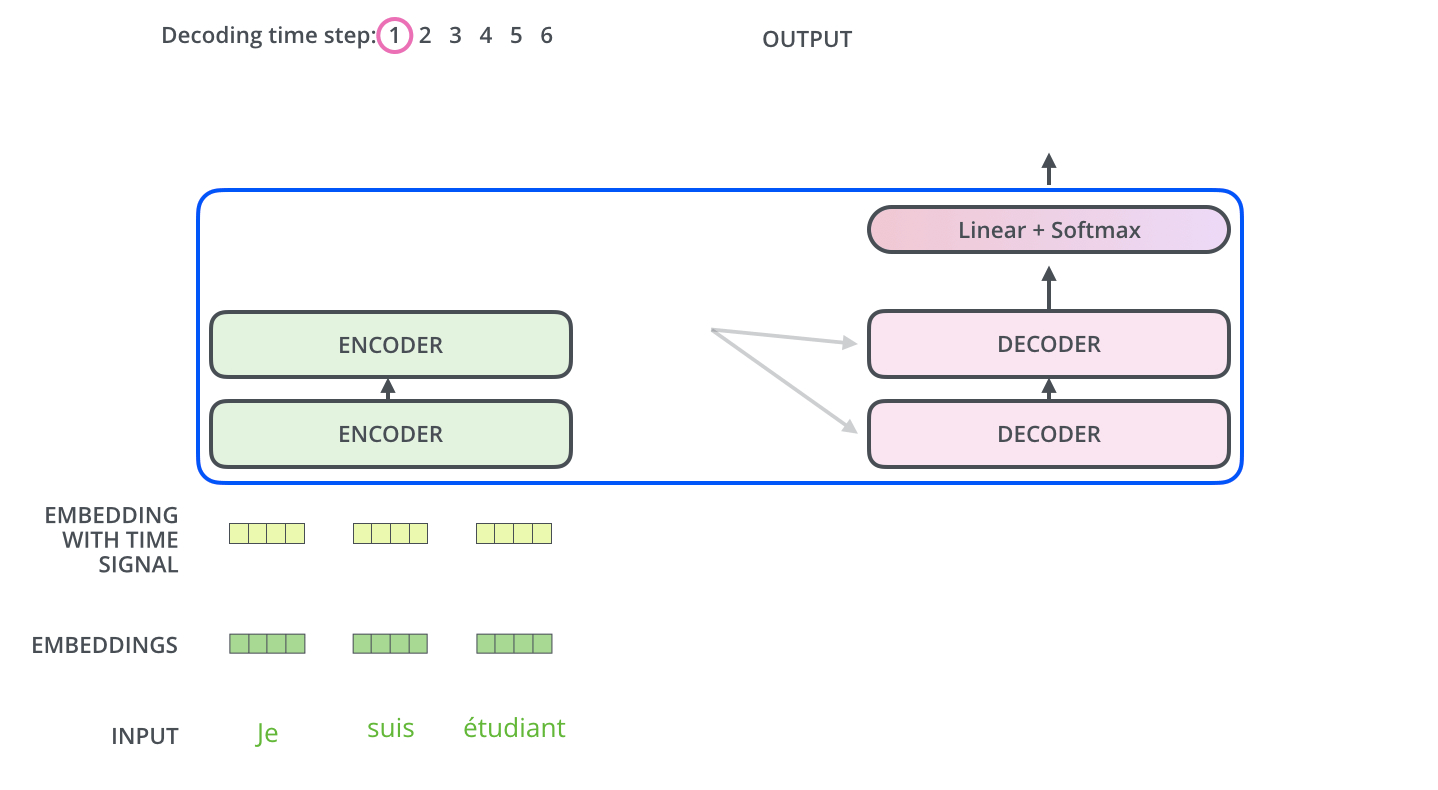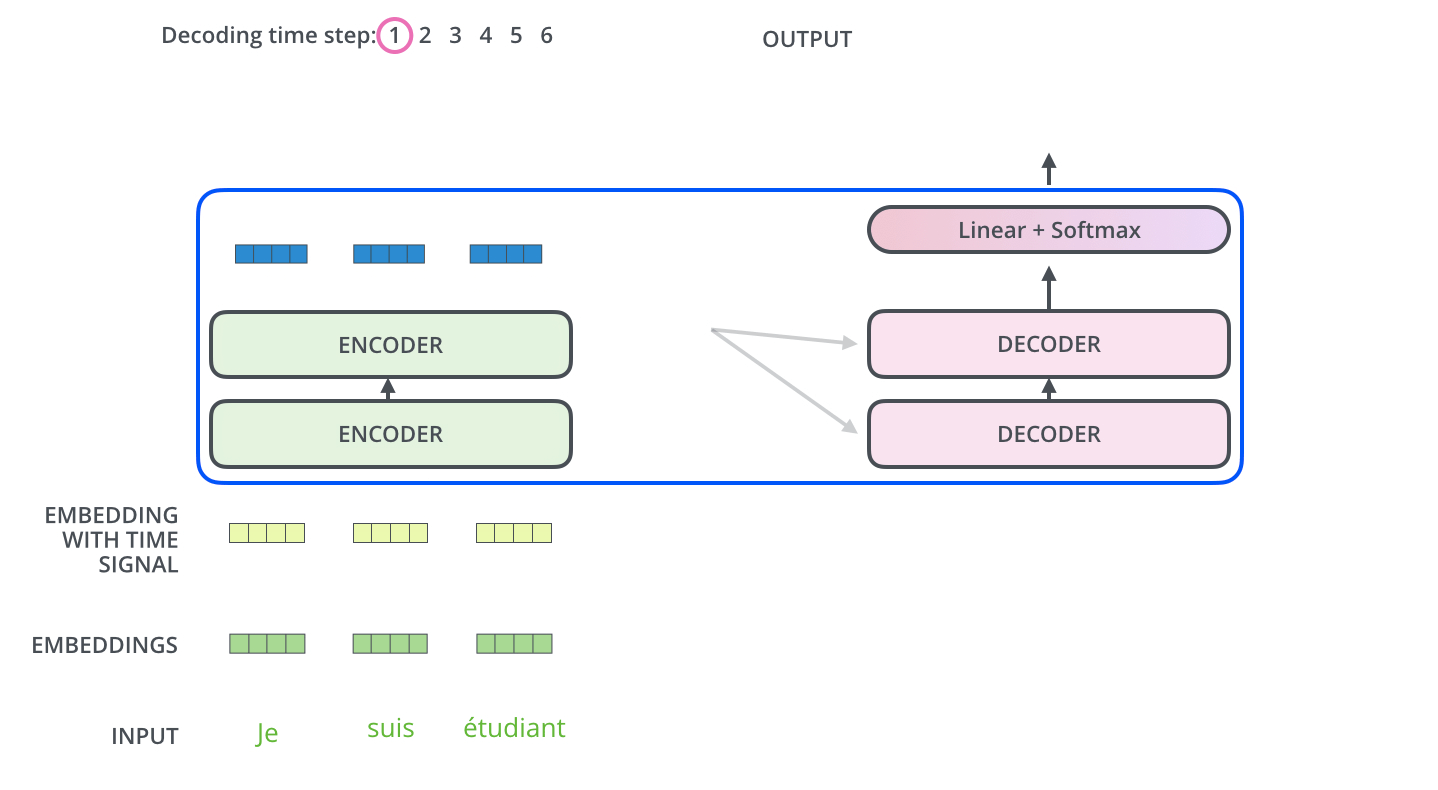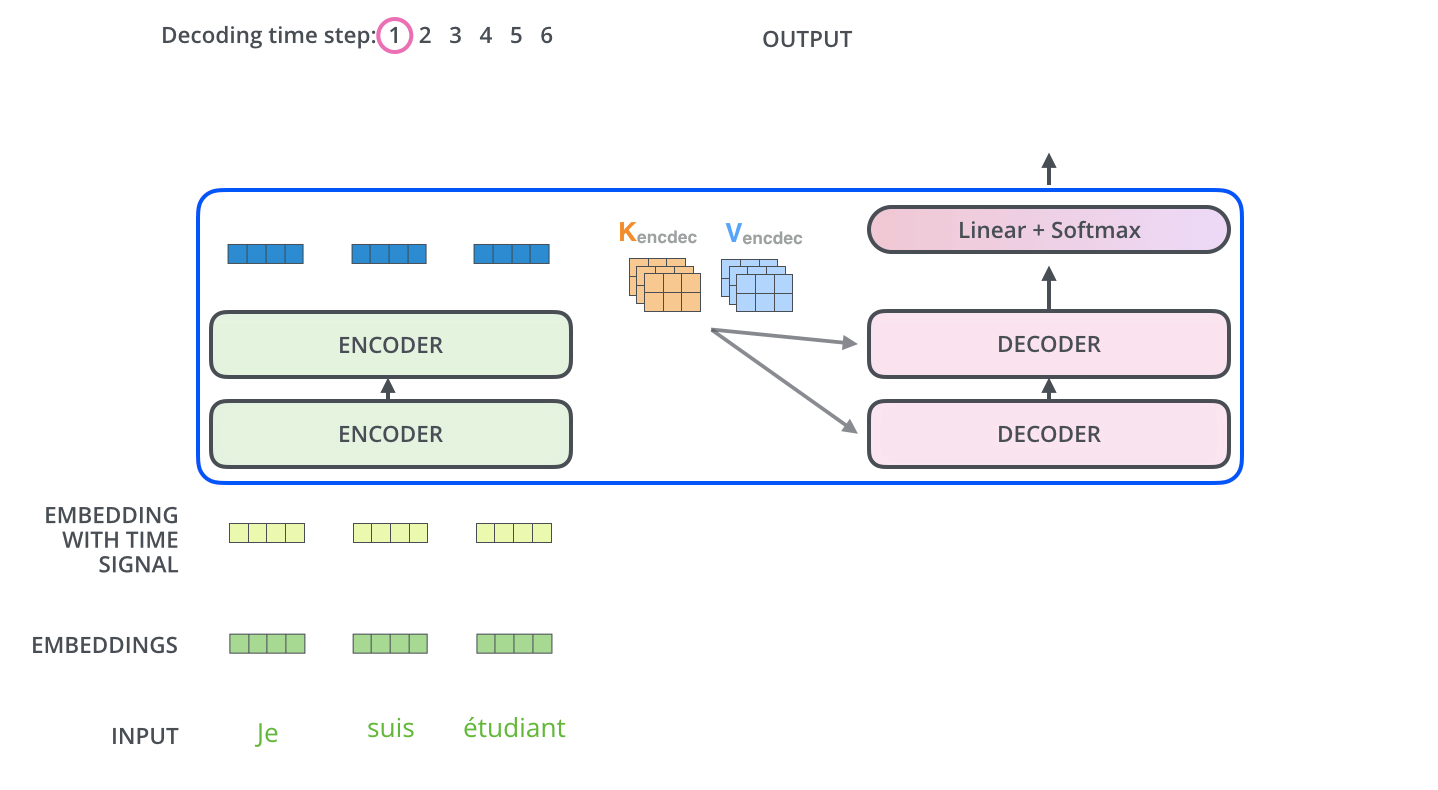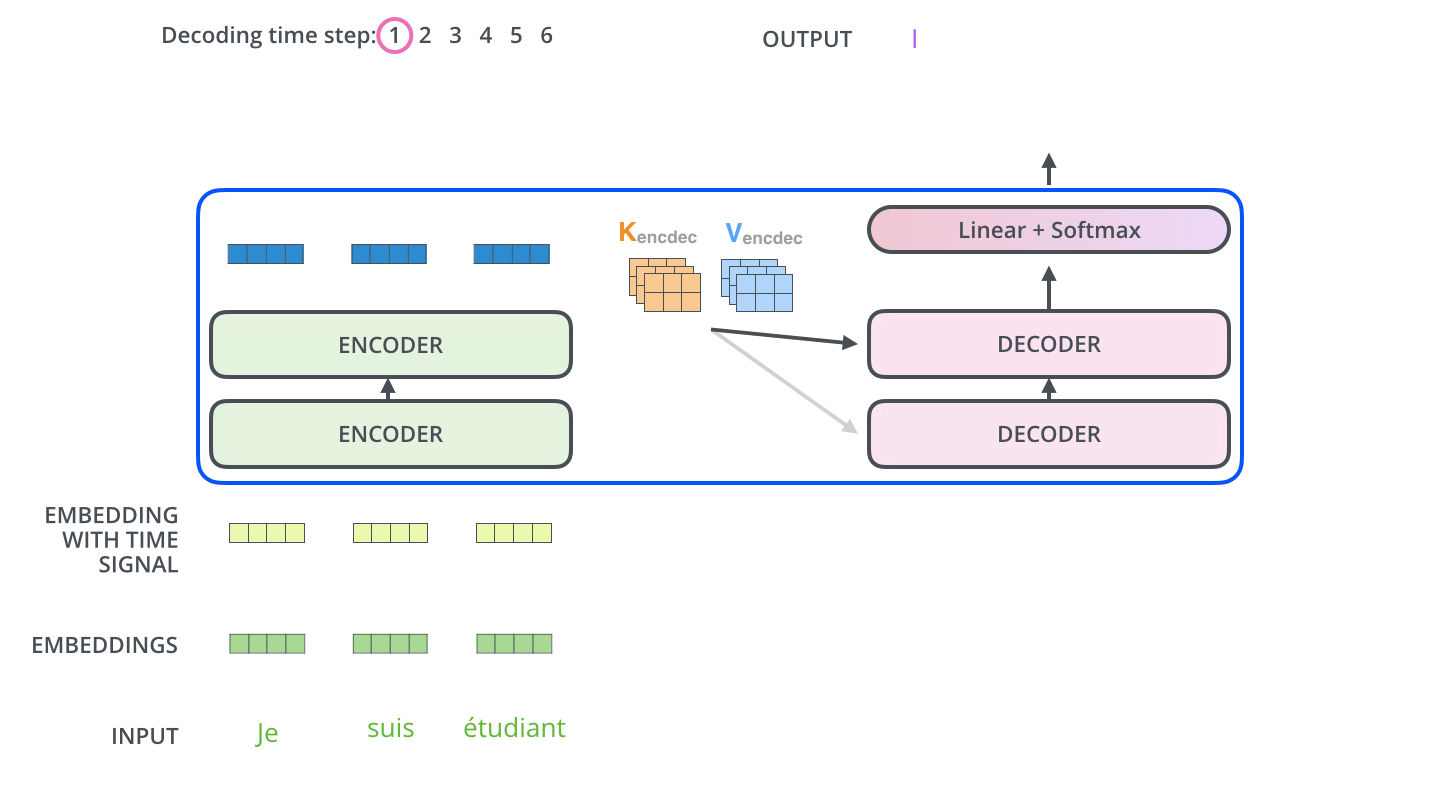
生成词
最终的向量通过线性层转化为词表的维度,做Softmax求最大概率的词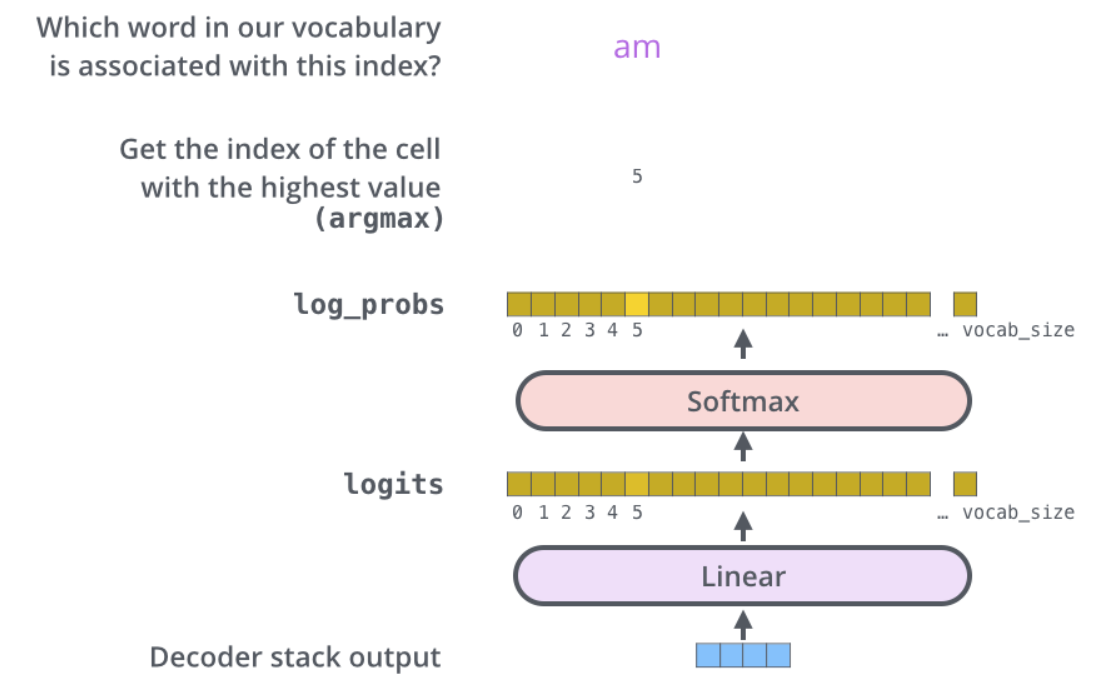
流程图: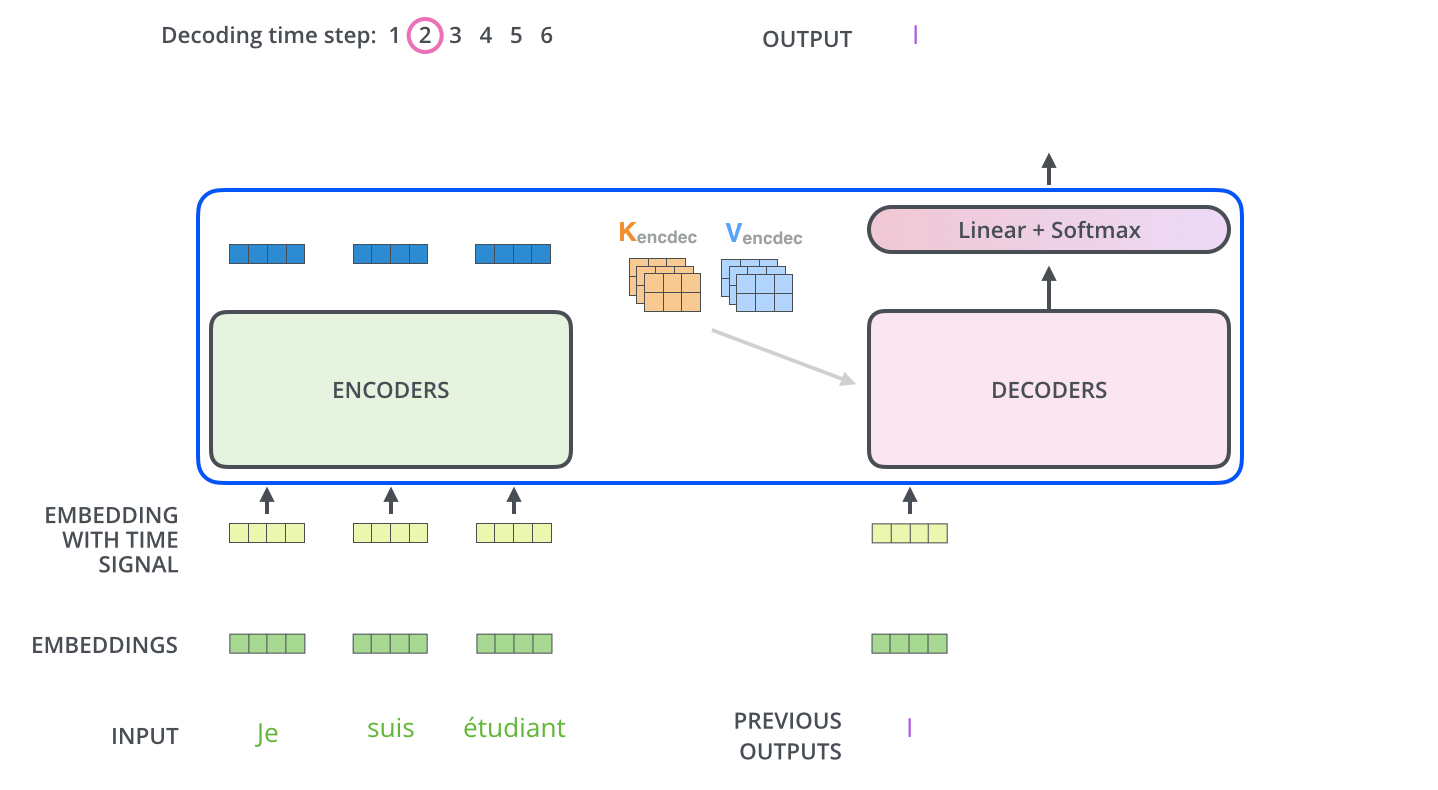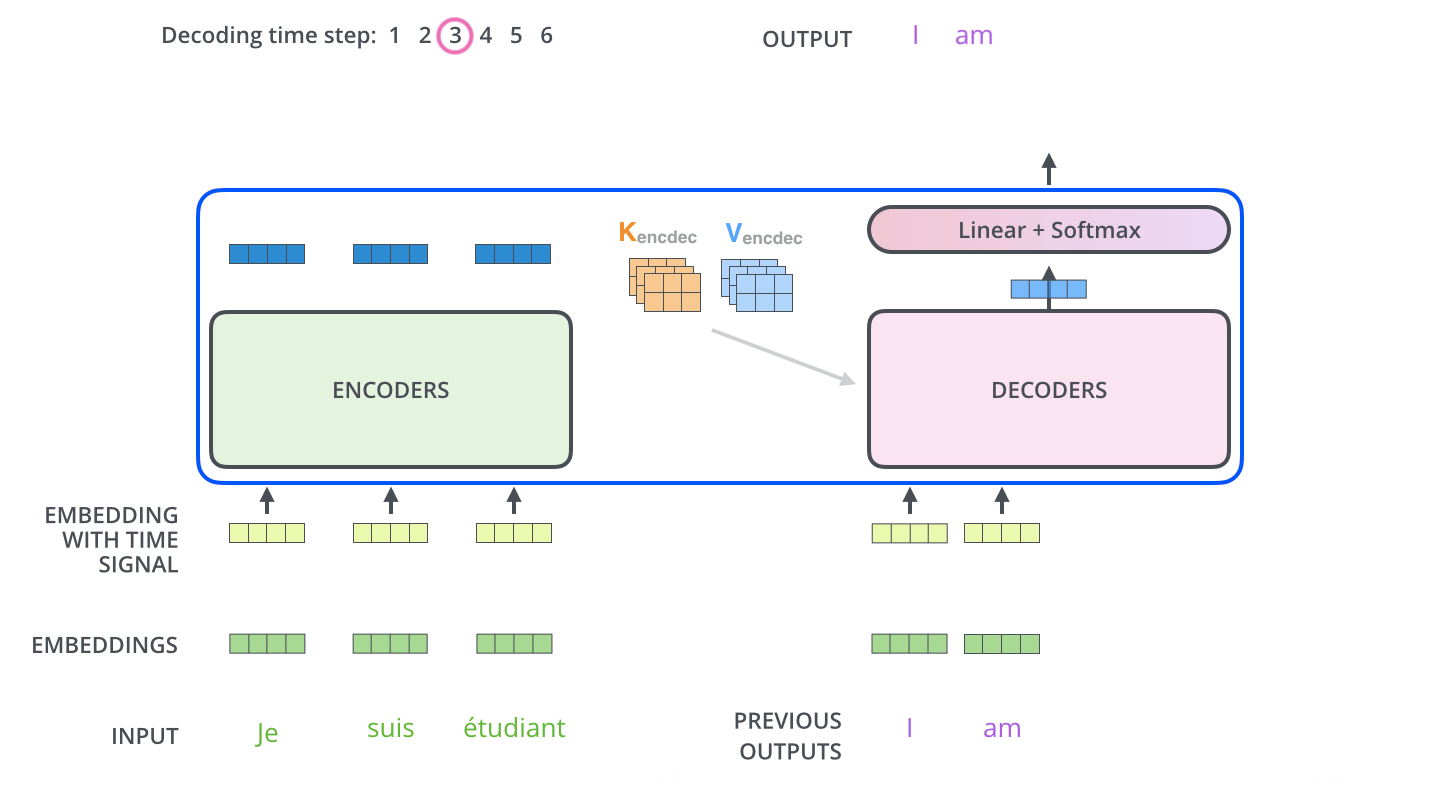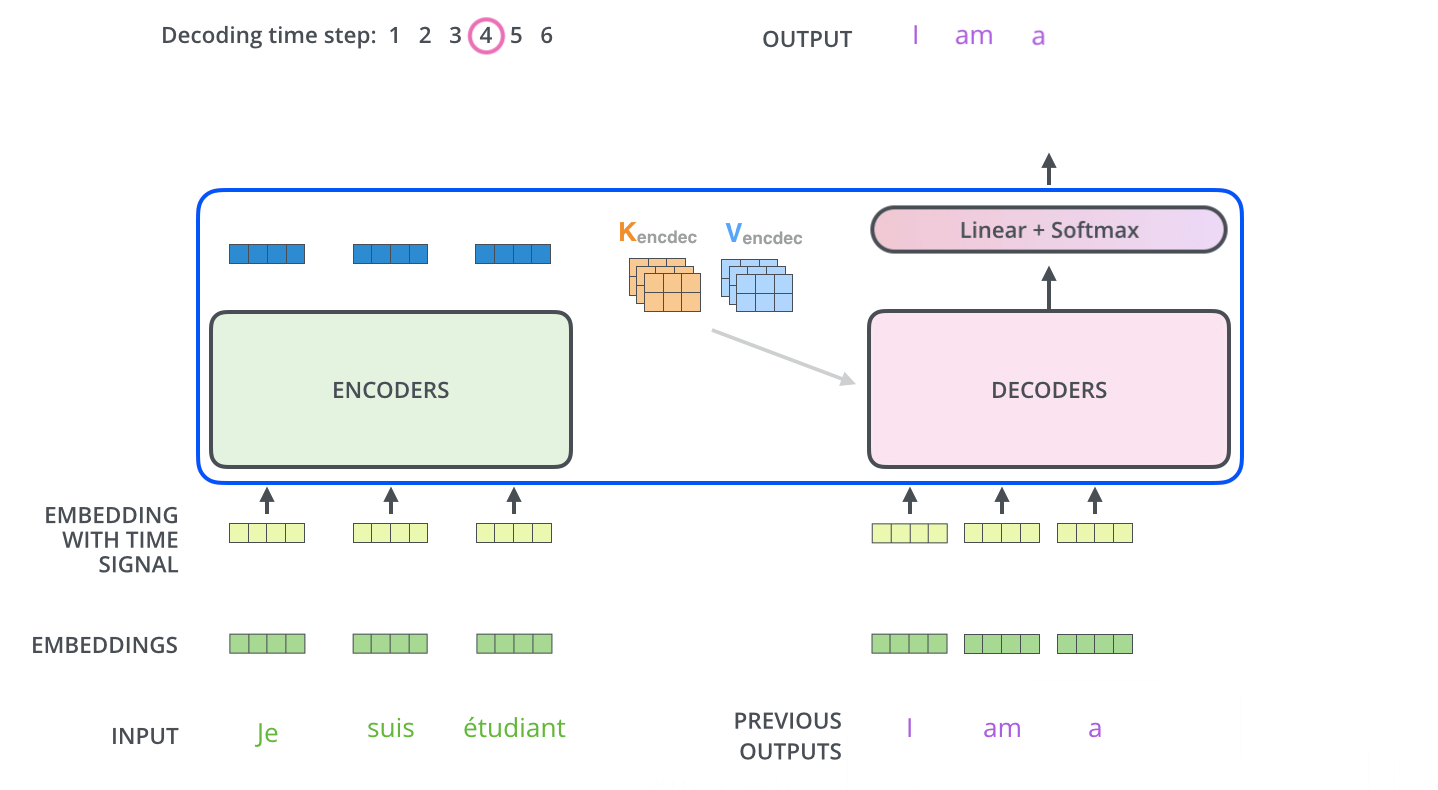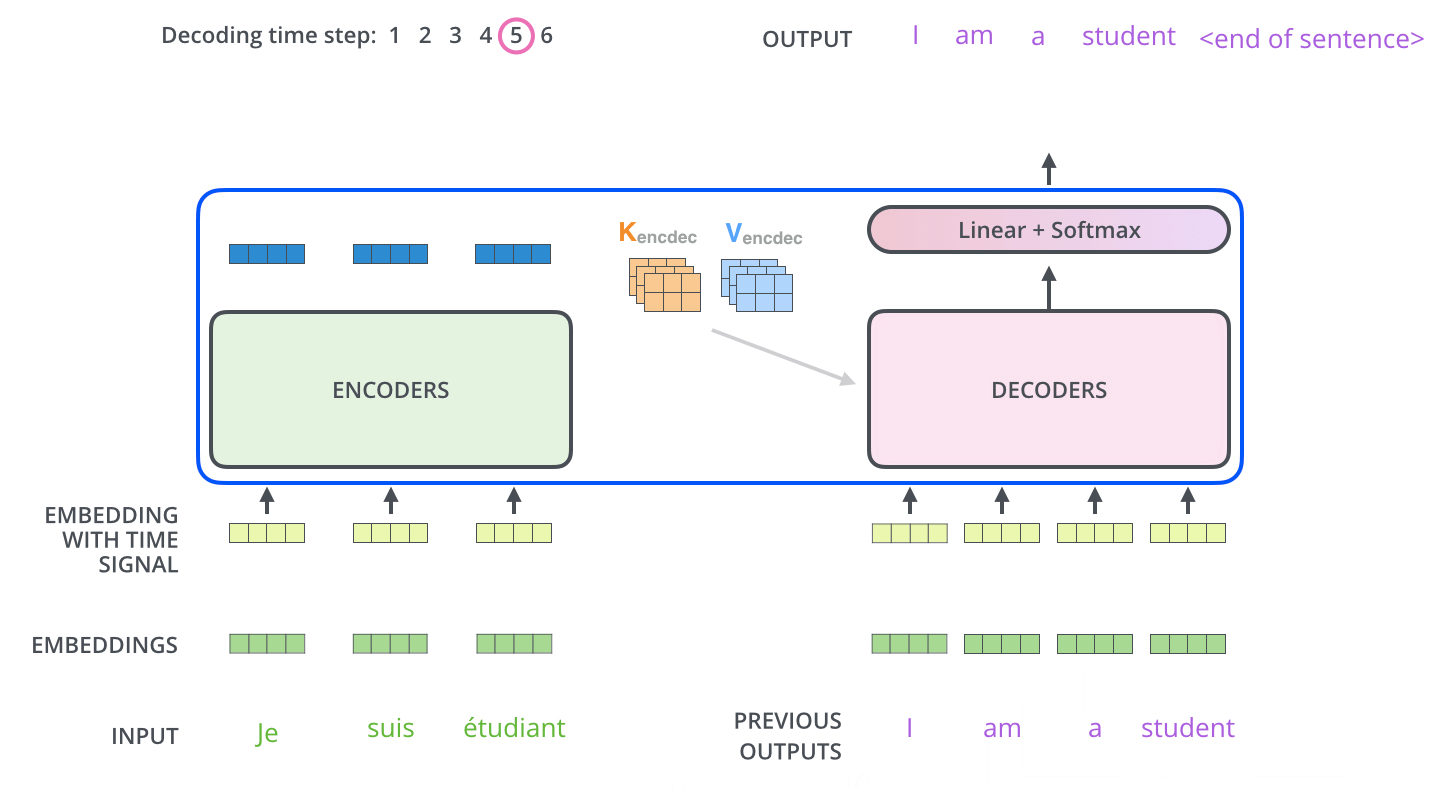
为什么Decoder要做Mask
为了解决训练阶段和测试阶段的Gap
- 训练阶段:解码器也会有输入(目标语句) 我爱你 - 》 I love you
- 目的:为了训练更新参数,降低损失
- 存在问题:实际测试阶段中,Decoder是不知道目标语句的,每生成一个词,就会放一个词进目标语句(只会把已经生成的词告诉解码器)
- 测试阶段:生成一个词,目标语句的词才会多一个
- 解决: Mask-Self-Attention (训练阶段)
- 生成第一个词的时候,什么也没有
- 生成第二个词,告诉第一个词
- 生成第三个,告诉前两个

为什么Enc给KV,Dec给Q
decoder中间有一个Encoder-Decoder-Attention,不是Self-Attention
Q来源于Decoder , K=V来源于Encoder
- Q是查询变量,即已经生成的词(目标词的一部分)
- K=V是源语句
作用:当我们生成了当前的词之后,通过把已经生成的词和源语句做注意力,确定源语句中哪些词语对接下来的生成更有作用
通过部分(生成的词)去整体(源语句)里面挑重点
解决了以前的Seq2Seq框架的问题:
lstm做编码器(得到词向量C),再用lstm做解码器生成
问题:
这种方法,每一次都是通过C的全部信息去生成,且容易信息丢失
一些小记录
在B站看到的一段话
人类大脑所谓的"理解",也不过是用一种感知去解释另一种感知,一切思维都必须借助某种具体的形式。
至于,你的这个瞬间的这种"生理感觉"到底是什么?我认为,这属于生物化学范畴,对于人工智能来说,并不重要。
当然,我个人把它叫做"存在",就如同一个量子、一个光子,它是那样的物质基础,就会有那样的属性、行为与现象,它不证自明。要知道,物自体不可知。
比如,你在阅读一首诗"林黛玉倒拔垂杨柳"的时候,试着【思维内视】你的大脑,你的脑海里会浮现一个画面,一个模糊的画面-“一位柔弱女子用手去拔树”。而此刻你的大脑经历的神经波动与你真的看到这个画面,是相同的,只不过是模糊版本的。
也就是说,你的大脑语言区把一个文本序列,像现在的大语言模型那样输入到你的大脑,然后经过大脑皮层高级区,映射为了一组视觉输出向量,此时你的感觉就如同真的看到一个模糊的画面。这便是文字与画面的互相解释。
记住,解释永远是「相对的」,你永远无法找到一个绝对的、静止的"认知以太"。
同时,正如文本形式的序列有它自身的规则,画面形式的序列同样有其特殊的规则,我自己给它取了一个名字,叫-【事件序列】。
正如,语音序列的最小单元是"音素",文本序列的最小单元是单词,那么事件序列的最小单元应该是"动作元"。比如,走、跑、接触、推动,等等。人工智能可以通过训练来掌握文本的语法规则,同样可以掌握「事件序列」的规则。
→这便是-“因果律”。
说到这里,我几乎已经把如何实现通用人工智能AGI的思路,说了一遍。
应用
Transformer的三类应用
- 机器翻译类 - 使用Encoder+Decoder
- 文本分类BERT和图片分类VIT - 只使用Encoder
- 生成类模型 - 只使用Decoder
