Pytorch学习
加载数据
Dataset 和 DataLoader
- Dataset:获取数据,label,数量
- DataLoader:加载数据,同时可以进行数据预处理
Dataset
Dataset 是一个抽象类,所有子类都应该重写 __getitem__ 方法; 可以选择性重写 __len__ 方法
__getitem__ : 返回数据及其label__len__ : 返回数据数量
简单示例
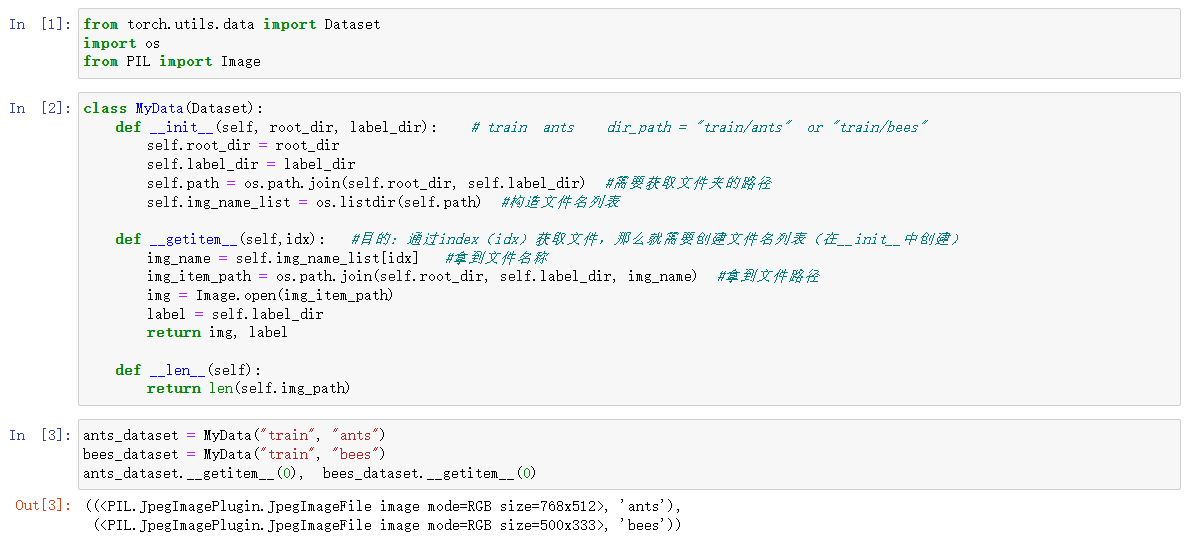
下面是一个简单获取图像数据集的示例(label为文件夹的名字,如果label是在txt中,那么获取到名字之后找到相应的 txt 文件拿到 label 即可)
关键代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_name_list = os.listdir(self.path)
def __getitem__(self,idx):
img_name = self.img_name_list[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
|
Jupyter演示:
DataLoader
后面单独讲
训练可视化
有时候需要根据模型的loss来挑选合适的模型,或者查看模型训练结果,使用下面几个方式可以直观的做出可视化
Tensorboard
Pytorch1.1之后加入了Tensorboard
安装:
pytorch导入包
1
| from torch.utils.tensorboard import SummaryWriter
|
读取标量
1
| add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)
|
1
2
3
4
5
6
7
8
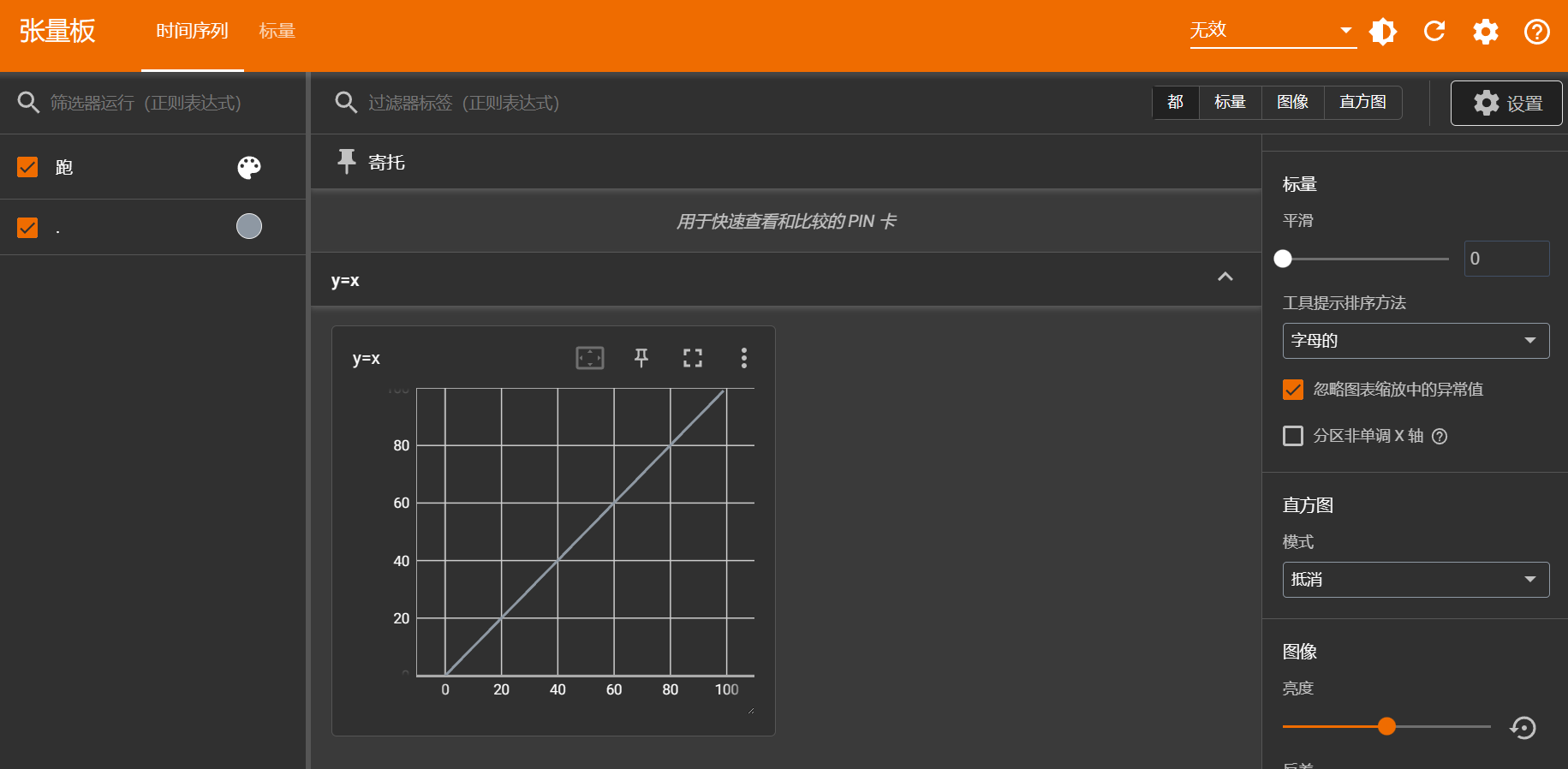
| writer = SummaryWriter("logs")
for i in range(100):
writer.add_scalar("y=x",i, i)
writer.close()
|
然后会在指定位置生成目录(这里是logs)及文件,可以在命令行输入:tensorboard --logdir=logs

也可以指定端口:tensorboard --logdir=logs --port=6007
读取图像
1
| add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
|
能读入的图像只能是以下几种类型:img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data
如何读取numpy型图像,可以利用opencv读取
也直接用numpy读取
导入numpy
1
2
| import numpy as np
from PIL import Image
|
1
2
3
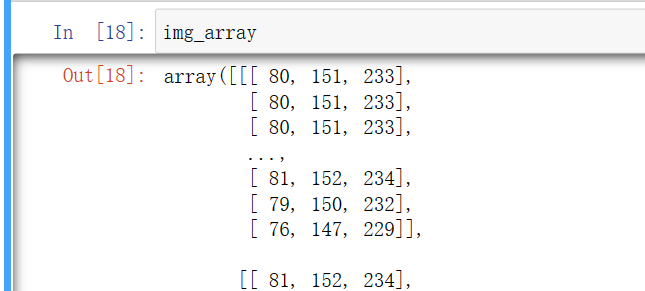
| img_path = "train/ants_image/0013035.jpg"
img = Image.open(img_path)
img_array = np.array(img)
|
使用Tensorboard
1
2
3
4
5
| writer = SummaryWriter("logs")
writer.add_image("test_image",img_array,1)
writer.close()
|
有时候图片shape不匹配(默认是CHW格式,chanel,height,width)会报错,在使用Tensorboard之前记得看一看图片shape,避免报错,比如我这张图片是HWC格式(通道Chanel在最后)
那么就要指定格式
1
2
3
4
5
| writer = SummaryWriter("logs")
writer.add_image("test_image", img_array, 1, dataformats="HWC")
writer.close()
|
然后可以在命令行输入tensorboard --logdir=logs 然后点击链接查看
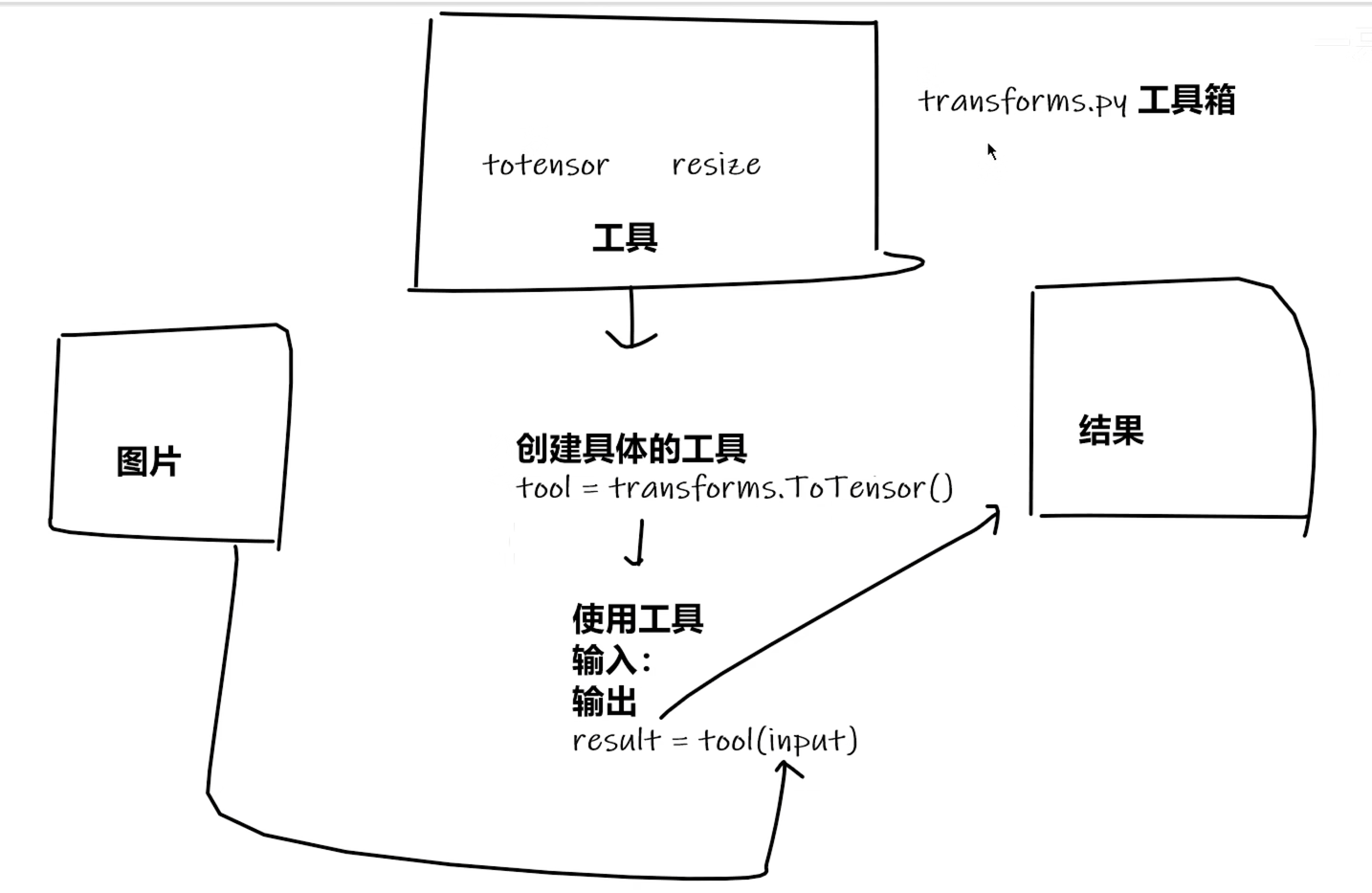
简单使用示例:
ToTensor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| from torchvision import transforms
from PIL import Image
img_path = "./练手数据集/train/ants_image/0013035.jpg"
img = Image.open(img_path)
img
print(img)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
tensor_img
|
结合Tensorboard
1
2
3
4
5
6
7
8
9
10
| from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img = Image.open(img_path)
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
writer.close
|
Normalize
1
2
3
| trans_norm = transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
img_norm
|
Resize
1
2
3
4
5
6
| print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
print(img_resize)
|
Resize输入两个参数时,输出的图片按照给定参数变化,如果只输入一个数字,比如Resize(512), 代表指定最短边的像素数量
Compose
参数是一个transform实例列表
1
2
| trans_compose = transforms.Compose([trans_resize, trans_totensor])
img_tensor = trans_compose(img)
|
前一个的输出是后一个的输入
数据集
torchvision里的数据集的使用
以CIFAR10为例
1
2
3
4
5
6
7
8
9
10
|
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset",
train=True,
download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
download=True)
|
1
2
3
4
5
6
7
| from PIL import Image
print(test_set[0])
img, label = test_set[0]
print(img)
print(label)
print(test_set.classes[label])
img
|
数据集默认为PIL图片,可以结合transforms转化为Tensor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import torchvision
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
])
train_set = torchvision.datasets.CIFAR10(root="./dataset",
train=True,
transform=dataset_transform,
download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",
train=False,
transform=dataset_transform,
download=True)
|
结合tensorboard可视化前十张图片
1
2
3
4
5
6
7
8
| from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("p10")
for i in range(10):
img, label = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
|
DataLoader
torch.utils.data — PyTorch 2.1 documentation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| import torchvision
test_data = torchvision.datasets.CIFAR10(
root="./dataset",
train=False,
transform=torchvision.transforms.ToTensor()
)
from torch.utils.data import DataLoader
test_loader = DataLoader(dataset=test_data, batch_size=4,
shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
print(test_data.classes)
|
1
2
3
4
5
|
for data in test_loader:
img, target = data
print(img.shape)
print(target)
|
搭建神经网络
torch.nn.Module
所有torch定义的网络都必须继承这个类
一个示例:
1
2
3
4
5
6
7
8
9
10
11
12
| import torch.nn as nn
import torch.nn.function as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1,20,5)
self.conv2 = nn.Conv2d(20,20,5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
|
卷积
torch.nn.functional.conv2d — PyTorch 2.1 documentation
以function.conv2d为例,注意这里的输入和kernel都是四维的,第一个表示batch数
1
2
| import torch
import torch.nn.functional as F
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
print(input.shape)
print(kernel.shape)
|
1
2
| output = F.conv2d(input, kernel, stride=1, padding=0)
print(output)
|
卷积层
卷积层在nn.Conv2d里面
Conv2d — PyTorch 2.1 documentation
1
| torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
|
这个kernel只需要设置大小,不需要设置具体值(由训练得到)
1
2
3
4
5
6
| import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
from torch.nn import Conv2d
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataLoader = DataLoader(dataset, batch_size=64, shuffle=True)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
return x
model = Model()
print(model)
for data in dataLoader:
imgs, targets = data
output = model(imgs)
print(output.shape)
|
优化器
在torch.optim里面
注意每一次反向传播之前,先清零梯度
略一下,可以看李沐的课程或者官网
使用torch的预训练模型
以VGG16为例
1
2
| import torchvision
import torch.nn as nn
|
1
2
3
4
| train_data = torchvision.datasets.CIFAR10("./dataset",
train=True,
download=True,
transform=torchvision.transforms.ToTensor)
|
1
2
3
4
5
6
|
vgg16_false = torchvision.models.vgg16(pretrained=False)
print("done")
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("done")
|
将VGG16更改为可以应用CIFAR10数据集模型
1
2
| vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
|
当然也可以更改未预训练的模型
1
2
| vgg16_false.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_false)
|
模型的加载和保存
1
2
3
4
| import torchvision
import torch
vgg16 = torchvision.models.vgg16(pretrained=False)
|
保存方式1
既保存网络模型结构,也保存网络模型参数
1
| torch.save(vgg16, "./models/vgg16_1.pth")
|
加载
1
2
| model = torch.load("./models/vgg16_1.pth")
print(model)
|
保存方式二(官方推荐)
只保存模型参数(状态),保存为字典
1
2
|
torch.save(vgg16.state_dict(), "./models/vgg16_2.pth")
|
加载
1
2
3
4
5
6
| model = torch.load("./models/vgg16_2.pth")
print(model)
vgg16_new = torchvision.models.vgg16(pretrained=False)
vgg16_new.load_state_dict(model)
print(vgg16_new)
|
注意的问题
在自己定义模型时(使用继承nn.Module)
方式一虽然会保存模型结构,但是仍然需要代码中有这个模型class类(相当于任然需要访问模型定义的代码)
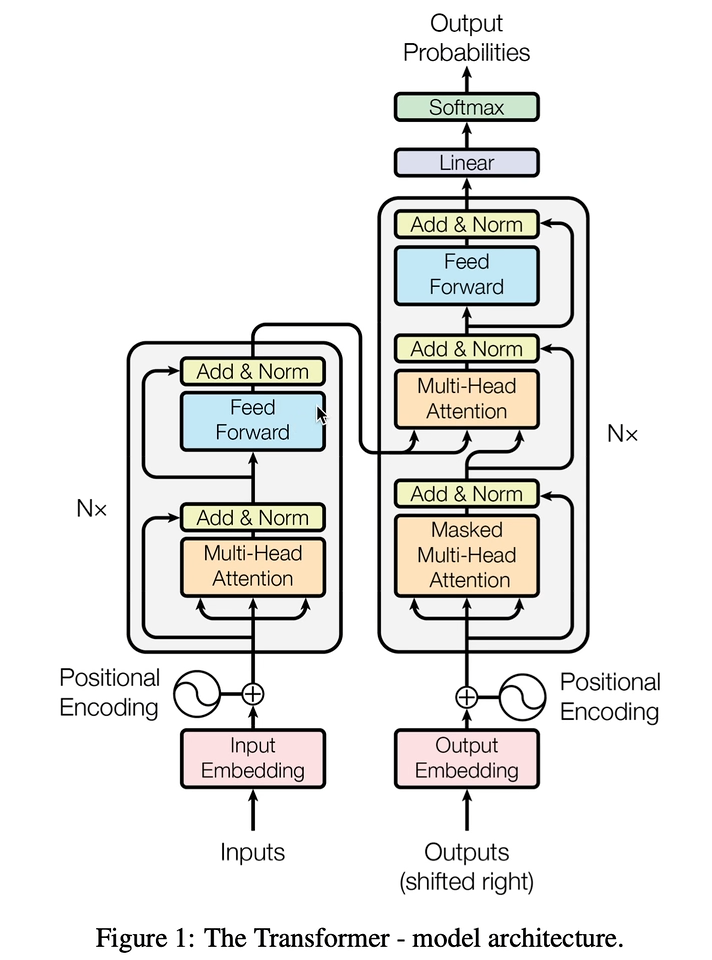
【18、深入剖析PyTorch中的Transformer API源码】https://www.bilibili.com/video/BV1o44y1Y7cp?vd_source=c2c8a4fe07a11ba495278ab92632a245
论文:[Attention is all you need]([1706.03762] Attention Is All You Need (arxiv.org))
Self-attention
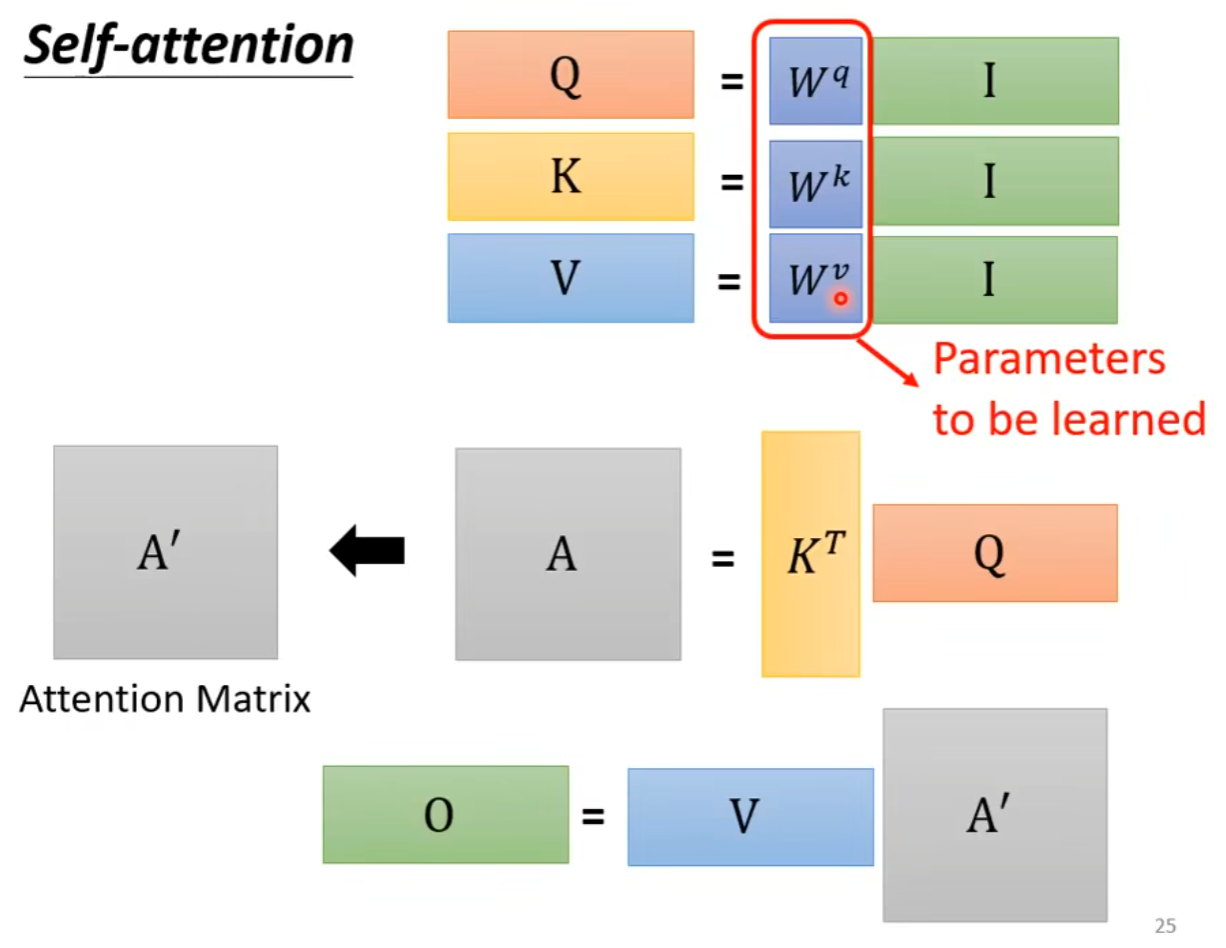
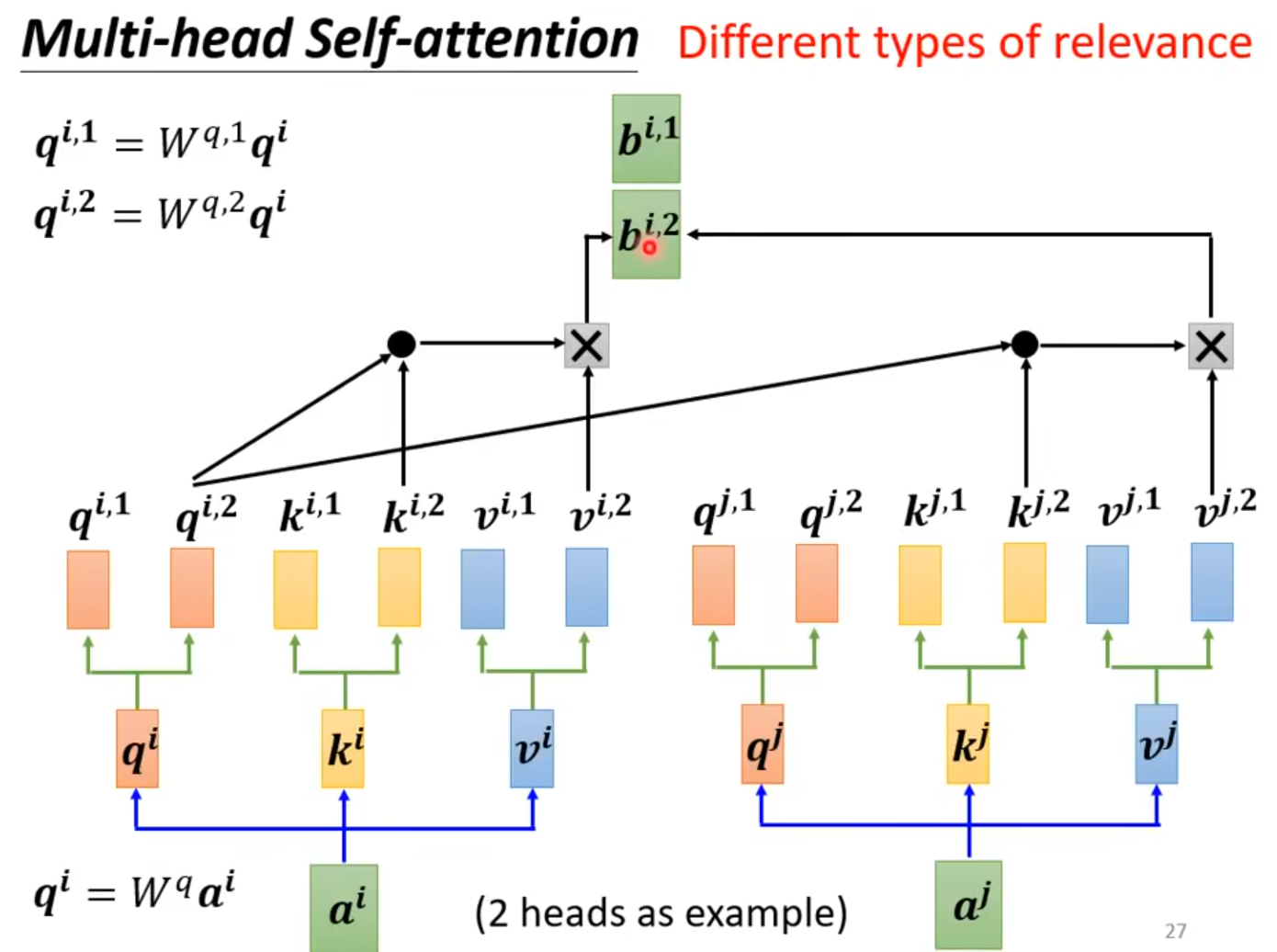

自注意力机制vsCNN
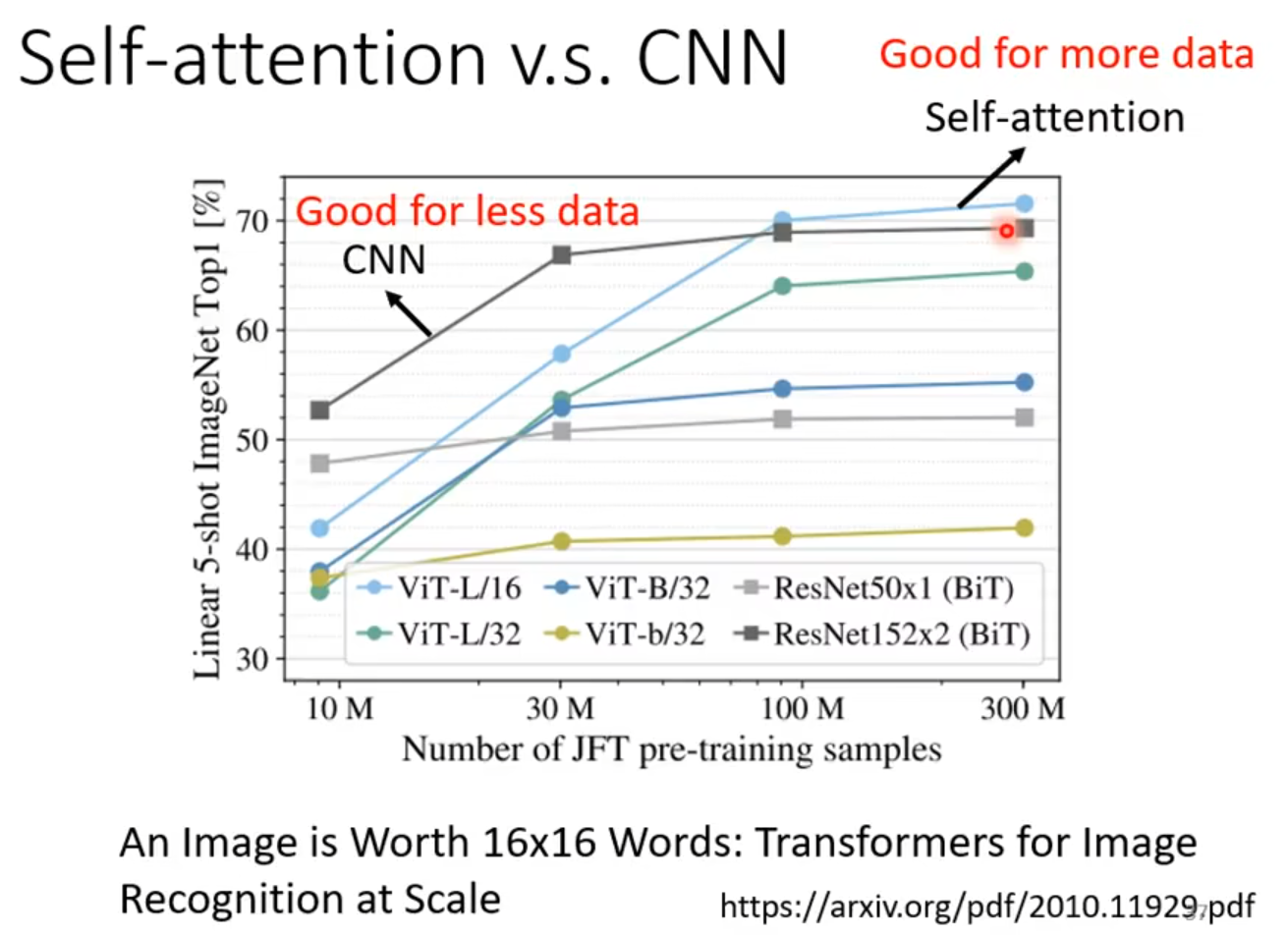
论文
vsRNN
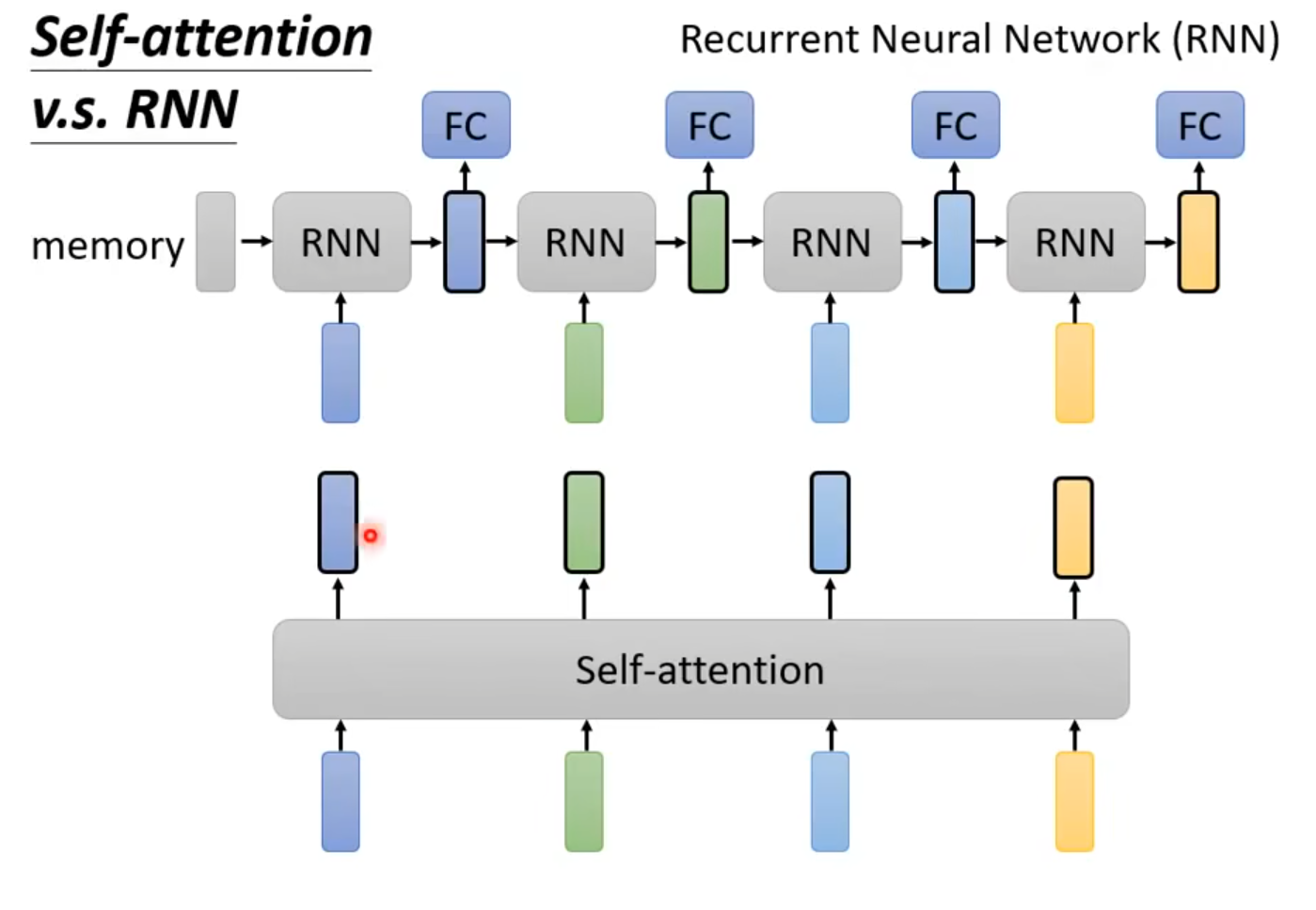
本质就是一个Seq2Seq模型